ベッドにスマホ/タブレット アームを取り付けてダメ人間になる
注意:就寝前にタブレットやスマホの光源を注視することは入眠速度や睡眠の質に悪影響を及ぼすという研究結果があります。真人間の皆様はどうか絶対に真似しないように。
ベッドでゴロ寝しながら画面を見るためのセットアップ
要約
運用イメージ


使用した製品
選択理由については後述。
メイン
- Unique Sprit社 アームスタンド

補助機器(手持ち)
- Bluetoothマウス。(ボタンが多いとBetter)

- 発売日: 2019/09/27
- メディア: Personal Computers
- スイッチのジョイコン
 ネオンパープル/(R) ネオンオレンジ")
【任天堂純正品】Joy-Con(L) ネオンパープル/(R) ネオンオレンジ
- 発売日: 2019/10/04
- メディア: Video Game
使用用途
上2つはBluetoothマウス使用。 読書に関してはスイッチのジョイコン使用。
セッティングと諸操作
手をなるべく楽にしたいのでBluetooth接続機器を使います。
マウス
Bluetoothで接続するとカーソルが出てPCのように使えます。手をベッドにつけたまま寝れるので便利です。
ボタンに対する操作の配置は以下のとおりです。Keymappingが使えるソフトがAndroidに来てくれれば捗るのですが…

Tips
- ちょっとした動画検索などは音声入力でできるので寝姿勢のまま作業できる
- 物理キーボードがあるときにも仮想キーボードを出す設定にしないと入力画面がでなくなる
スイッチのジョイコン(左)
ジョイコンもBluetoothでPCやAndroidにつなげられます。ボタン配置的には左のほうがしっくり来ます。
- ジョイコンでのアンドロイド操作(完全にはよくわかってないです)

こちらはカーソルが出ないので基本マウスの劣化なのですが,Kindleで読書するときだけはこちらのほうが便利です。
なぜなら,スティックを倒すだけでページがめくれるからです。(マウスだとクリックしてドラッグする必要がある。)
これ単体は安くないのでスイッチを持っている人向けではあります。なおプロコンでも同様のことができます。
感想
案外自分は普段横向きに寝て機器をいじるので上向きはあんまり落ち着かない(電球とかぶる問題もある)という問題はありますが概ね快適に使えています。
ポジティブ
- 端末を支えるために変な姿勢を無理に取らないので首や肩周りが楽
- 横に向けたときもGood
- 上向きで寝ない人には良い矯正になりそう
- 地面におく,立てかける以外の画面固定法があるのは以外にも便利
- 寝ながら足を上げて腹筋する系の動画の運動を自然に行える
- マルチ画面操作(動画見ながらXX)みたいなのが捗る
ネガティブ
- 案外寝転がって動画を見るとかは長時間できない(多分腰に来てる)
- 画面の姿勢や位置を変えるのは手間
- 操作時に手を上げるのが手間 → マウスで解決 → マウス持ってくるのが(略
- 可動部が狭い。基本取り付けた部分より高い場所にしかアームはいかない。
考察
買った製品の評価
普通に使えると思いますがアームの可動範囲など注意する点もあります。
ポジティブ
- 案外安定感は高い
- 先端部分がボールジョイントで自由度が高いのは良い
ネガティブ - つくりのちゃちさ - タブレットホルダーが挟み込むタイプにしてはちょっとちゃちい。ずり落ちが怖いので縦向きにしたくない。 - 根本のクランプとの接続部分が簡素すぎてちょっと怖い。固定用ネジの先端を加工してくれると良かった。 - 耐荷重とかを気にした結果,値段がそれなりにする。 - 箱がやたらでかい
商品選択理由補足
この手のアームにはフレキシブルアームとジョイント式のアームがあります。
フレキシブルアーム型
関節駆動型


| フレキシブルアーム | 関節駆動 | |
|---|---|---|
| 値段 | 安め | 高め |
| 姿勢自由度 | 高い | 制約あり |
| 姿勢の固定 | できる | しやすい |
| 姿勢の変更 | できるが難しい | ネジを調整する必要有 |
ちょっとお金出しても良くて,姿勢をしっかり固定したいならやはり関節駆動のタイプになると思います。
ぶつけたときの痛さは関節駆動の方が痛いと思うのでドジっ子,安いほうがいい子はフレキシブルアームで。
その他の要素
- 根本固定方法:机とかでも使うならクランプ式が良いと思います。スタンドタイプは重かったりするし。
- 画面の把持方法:しっかり挟み込めるほうが良いです。クリップ式は一度破壊したことがあるのでおすすめしません。
おまけ:類似のセットアップについて
結構快適だったのですが欲を言えば画面をでかくしたくなりました。
類似の事例として以下のものを試したり試さなかったりしました。
VR ゴーグル(既トライ)
以前VRゴーグルで似たようなことをしていたことがあります。
電球が眩しくなく,没入感が高い反面,目が疲れて結果的にはそこまでリラックスできなかった記憶があります。
 - 64 GB")
【正規輸入品】Oculus Go (オキュラスゴー) - 64 GB
- 発売日: 2018/12/20
- メディア: Video Game
天井プロジェクター (未トライ)
天井が白ければ天井プロジェクターも良さそうです。
プロジェクターの排熱とファンの騒音がやや問題ですがガジェットとして正直欲しい面もあります。

モニターアーム+ Chromecast系(未トライ)
モニターアームにモニターつけてChromecastすれば手元のスマホで操作できて快適??とも思いますが寝る時にディスプレイが上にあるのは地震大国ではちょっと怖いですね…

エルゴトロン LX デスクマウント モニターアーム アルミニウム 45-241-026
- 発売日: 2010/03/09
- メディア: Personal Computers

Google Chromecast 正規品 第三世代 2K対応 チャコール GA00439-JP
- 発売日: 2020/03/01
- メディア: エレクトロニクス
Ubuntu 18.04 リモートデスクトップ接続のための サーバー構築
筆者の使用環境
ubuntuへのリモートデスクトップ接続は毎回苦労した記憶がありますが肝心の設定はすぐに忘れてしまうのでここに記します。
現在は以下のような構成でWindows10からUbuntu18にリモートログイン作業をしています。
- サーバー側(ホスト):Ubuntu18.04
- クライアント側:Windows10 Enterprise
- Viewer:リモートデスクトップ
所要時間はストレートに行けば15分〜30分といったところでしょうか。
環境比較と参考文献
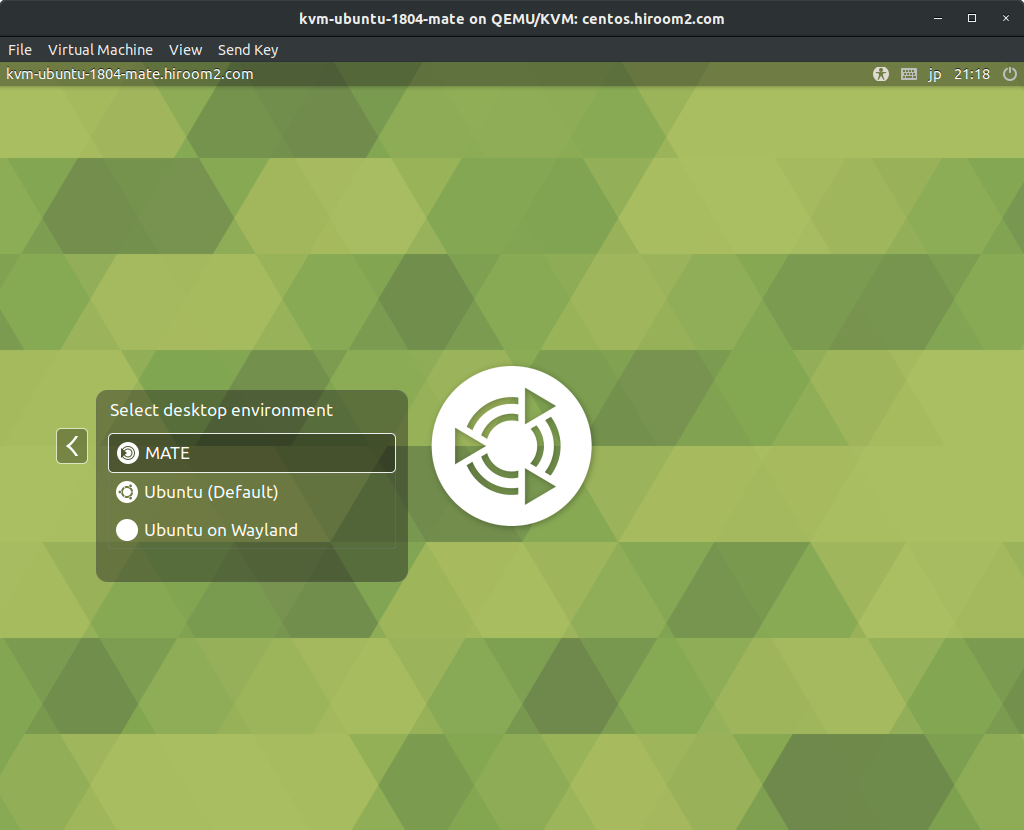
以前jetsonでやっていたときなどは軽さを重視してxfce4を使っていましたがUIイマイチなので見た目を重視したUbuntu MATE(マテと読むそうです)を使います。
主に以下のサイトを参照しました。
Ubuntuの画面共有設定
本格的な設定の前の下準備です。なお,今後特に断りがないコードはbashのコマンドとします。
画面共有の有効化

-「設定」→「共有」→「画面共有」から画面共有をアクティブにする。
- 「パスワードを要求する」にチェックを入れる。
- もし「共有」→「画面共有」の項目がない場合,sudo apt install vinoを実行して設定を開き直す。
参考:lowreal.net
一度ここで再起動をしたほうがいいです。
再起動後,リモートログインの項目が現れて「共有」がOFFになっているので改めてONにします。

暗号化処理をOFF,ファイヤウォールのポート開放
- 通信の暗号化処理をOFFにします。
sudo gsettings set org.gnome.Vino require-encryption false
- ファイヤウォールの状態を確認
sudo ufw status
これが非アクティブとでたら下を飛ばして次に進みます。
- ファイヤウォールがアクティブのとき5900番ポートを開ける
sudo ufw allow 5900 sudo ufw reload sudo ufw status
万が一,Windowsからの接続がうまく行かない場合,思い切ってufwをOFFにできます。
sudo ufw disable
もちろんsudo ufw enableでもとに戻すこともできます。
寄り道:SSHサーバーの設定
どうせSSHもたまに使うことになるので同時に入れておきます。
sudo apt-get install openssh-server
SSHのポートは22であることが通例なのでそちらも開けておきます。
sudo ufw allow 22 sudo ufw reload sudo ufw status
SSHがつながればscpなどでファイルを送りつけたりいろいろ便利です。
XRDPまわりの設定
1. Ubuntu MATEのデスクトップ環境をインストール
自分が最初一番ハマったのはここでした。以下でいろいろ設定するのですが,肝心のMATEの環境がないのを忘れたまま実行した場合VNC errorといったErrorが出現し,それに延々悩まされていました。
実際には以下のコマンドを叩くだけです。
sudo apt install -y ubuntu-mate-desktop
途中で,
check for a default display manager. 1. gdm3 2. lightdm
のような記述がでるかと思いますが,リモート用なので軽量のlgithdmを選択しました。
2. xrdp, Tiger VNCのインストールと設定
ここからは文献1の「えんでぃ」氏のコメント通りに進めます。 xrdpをインストールします。
sudo apt install -y xrdp sudo sed -e 's/^new_cursors=true/new_cursors=false/g' \ -i /etc/xrdp/xrdp.ini sudo systemctl enable xrdp sudo systemctl restart xrdp
TigerVNCをインストール
sudo apt install -y tigervnc-standalone-server
3. xrdpの初期設定をする。
XDG_DATA_DIRS=/usr/share/mate:/usr/share/mate:/usr/local/share
XDG_DATA_DIRS=${XDG_DATA_DIRS}:/usr/share:/var/lib/snapd/desktop
cat <<EOF > ~/.xsessionrc
export XDG_SESSION_DESKTOP=mate
export XDG_DATA_DIRS=${XDG_DATA_DIRS}
export XDG_CONFIG_DIRS=/etc/xdg/xdg-mate:/etc/xdg
EOF
4. ~/.xsessionの編集
~/.xsessionを編集して以下のようにします。root権限が必要です。
viが無難ですがgeditやcodeの方が初心者には使いやすい気もします。こわいお兄さんに言ったら怒られる可能性もありますが*1sudo gedit ~/.xsessionで良いでしょう。
~/.xsessionの変更後
unset DBUS_SESSION_BUS_ADDRESS export GTK_IM_MODULE=fcitx export QT_IM_MODULE=fcitx export XMODIFIERS="@im=fcitx" exec mate-session
5. /etc/xrdp/startwm.shの編集
日本語化やバグ取りに必要だった手順です。
sudo gedit /etc/xrdp/startwm.shを実行し文末手前に以下の部分を追加。
# 以下追加分 export GTK_IM_MODULE=ibus export QT_IM_MODULE=ibus export XMODIFIERS="@im=ibus" ibus-daemon -d unset DBUS_SESSION_BUS_ADDRESS exec mate-session # ↑コピーここまで # 以下元からある部分 test -x /etc/X11/Xsession && exec /etc/X11/Xsession exec /bin/sh /etc/X11/Xsession
6. /etc/xrdp/xrdp.iniの設定
sudo gedit /etc/xrdp/xrdp.iniを実行後開いたファイルに対して以下の文を[Xorg]の行の前に挿入します。
自分の場合目安として156行目に入れました。
[Xvnc] name=Xvnc lib=libvnc.so username=ask password=ask ip=127.0.0.1 port=-1 #xserverbpp=24 #delay_ms=2000
7. bashrcの変更
fcitx > /dev/null 2>&1
再起動
sudo service xrdp restart
補足
繋がらないときのTips
エラーの原因は結構しょうもないことの方が多かったりします。
- pingはお互いつながるか?
- 実行し忘れた項目がないか?
apt update & apt upgradeやrebootで治ったりもする- とりあえず
sudo service xrdp restartしてみる
など。
*1. sudo権限で編集,作成したファイルはroot権限のないエディタなどから編集できなくなるから(rootがあれば権限はまたいじれる)。ですよね?
Twintを使ってTweet情報を収集する(Python3)
前回の補足のような記事です。
概要
- Python上で使えるTwintパッケージを用いてTweet情報を収集する
- Twintを使って特定ユーザのTweetを収集する
- TweetsScraperに比べてデータ取得範囲が広い(自分への返信も見れる)
関連記事
- Tweetscraperを用いた場合
Python環境でのインストールと使い方
pipを用いてインストールして実行する場合
- 環境(イメージ):python:3.7-slim-stretch
- 5分足らずでインストール・実行可
インストールは以下のコマンドでできました。
pip3 install --user --upgrade git+https://github.com/twintproject/twint.git@origin/master#egg=twint
特定のusernameを検索するなら
twint -u username -o output.json
とすれば該当するusernameで検索できます。
コマンドは公式を見ましょう。
Dockerイメージをpullして実行
自前でDockerimageをビルドするかDocker Hubから引っ張ってくる事ができます。 どちらも試しましたが後者がおすすめです。
自分の場合は以下のlatestのimageを用いました。
使い方は簡単で以下のコマンドを実行すれば/dataというフォルダにoutput.jsonが生成されます。
docker pull x0rzkov/twint:latest docker run -ti --rm -v $(pwd)/data:/opt/twint/data x0rzkov/twint:latest -u <USERNAME> -o output.json --json
より詳細な説明は以下を参照してください。
Pythonで出力ファイルを確認
Pythonで出力を確認します。
ファイルごとopenしてjson.load()した場合,様式についてエラーが出ます。
中身をよく見ると1行毎にjson形式で書かれていてリストの形になっていないためのようなので下記のように一行一行読んで行きます。
import json data=[] with open("output.json", 'r',encoding="utf-8") as f: for line in f: data.append(json.loads(line))
TweetsScraperとの比較
得られる情報はほとんど遜色がなく,linkがurlsになっていたりtweet_idがconversation_idになっていたりなど細かいものが多いです。
一番大きな変更点は,自分への返信Tweetも取得できている点です。
{'cashtags': [], 'conversation_id': '1289395426723016708', 'created_at': 1596250862000, 'date': '2020-08-01', 'geo': '', 'hashtags': [], 'id': 1289395689697337344, 'likes_count': 3, 'link': 'https://twitter.com/slam_hub/status/1289395689697337344', 'mentions': [], 'name': 'SLAM-Hub', 'near': '', 'photos': [], 'place': '', 'quote_url': '', 'replies_count': 0, 'reply_to': [{'user_id': '1244129482132209664', 'username': 'slam_hub'}], 'retweet': False, 'retweet_date': '', 'retweet_id': '', 'retweets_count': 2, 'source': '', 'time': '03:01:02', 'timezone': 'UTC', 'trans_dest': '', 'trans_src': '', 'translate': '', 'tweet': 'PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding (ECCV2020)\nPaper: https://arxiv.org/abs/2007.10985\xa0', 'urls': ['https://arxiv.org/abs/2007.10985'], 'user_id': 1244129482132209664, 'user_rt': '', 'user_rt_id': '', 'username': 'slam_hub', 'video': 0}
これにより,会話をトラッキングできたり,conversation_idにより補足情報を関連付けることができます。
例えば,
# conversation_idを記録 ids = [] for dic in data: ids.append(dic['conversation_id']) # idの出現回数を数える from collections import Counter Counter(ids)
とすれば,会話毎に何Tweetあるか確認できます。
Counter({'1247356052657455105': 1,
'1248070308080177152': 2,
'1248436573865041920': 2,
'1248796223961624576': 2,
'1249155400122994688': 1,
'1249517662847283201': 2,…(以下略)
SLAM_HUBさんのTweetをスクレイピングしてmarkdown資料(Marpスライド)形式にまとめる
勢いで作りましたがまだ@slam_hubさんの許可をもらってないので場合によっては後で消します><
許諾をいただきました。どうもありがとうございます!
概要
- 特定のTwitterアカウントからTweetを抽出
- YoutubeやArxivのURLから画像やタイトルを抽出
- 整形してMarkdown(Marpスライド形式)にて吐き出す
- 作業環境:Python3.7 on Windows10,+ Docker環境
こうなる

工程
- Tweet情報を抽出
- リンクのURLからコンテンツを抽出
- データ選別など後処理
- 整形,文章作成
Twitter情報を抽出
TwitterからTweetをスクレイピングします。ざっと思いつく手法は以下の通り。
- Twitter APIを使う方法 PythonによるWeb API(4) 指定したツイッターアカウントのツイートを全抽出する|Dai|note
- TweetScraperを用いる方法
- TwitterScraperを用いる方法
基本的には最近面倒になったTwitter APIの申請が必要ですが,いくつか抜け道もあるようです。
ここでは以下の記事で取得したツイート群を使用します。
このTwitterScraperで抽出したjsonファイルは辞書型の要素を詰めたリストになります。(長いので詳細を御覧ください)
{'has_media': True, 'hashtags': [], 'img_urls': ['https://pbs.twimg.com/media/Ec2t_Y-UcAAYEyM.png'], 'is_replied': True, 'is_reply_to': False, 'likes': 26, 'links': ['https://arxiv.org/abs/2004.01793'], 'parent_tweet_id': '', 'replies': 1, 'reply_to_users': [], 'retweets': 9, 'screen_name': 'slam_hub', 'text': '画像からの物体方向推定を,self-supervisedに学習する枠組みを提案.画像から3次元方向とスタイル特徴量を抽出し,それらの潜在変数を元に幾何学的変換を行うGenerator(GAN)を用いて学習.損失には一貫性と水平対称性を利用し,教師あり学習に匹敵する性能を達成.\nhttps://arxiv.org/abs/2004.01793\xa0pic.twitter.com/Qr4LM3uTxA', 'text_html': '<p class="TweetTextSize TweetTextSize--normal js-tweet-text tweet-text" data-aria-label-part="0" lang="ja">画像からの物体方向推定を,self-supervisedに学習する枠組みを提案.画像から3次元方向とスタイル特徴量を抽出し,それらの潜在変数を元に幾何学的変換を行うGenerator(GAN)を用いて学習.損失には一貫性と水平対称性を利用し,教師あり学習に匹敵する性能を達成.\n<a class="twitter-timeline-link" data-expanded-url="https://arxiv.org/abs/2004.01793" dir="ltr" href="https://t.co/rEGIDLI41f" rel="nofollow noopener" target="_blank" title="https://arxiv.org/abs/2004.01793"><span class="tco-ellipsis"></span><span class="invisible">https://</span><span class="js-display-url">arxiv.org/abs/2004.01793</span><span class="invisible"></span><span class="tco-ellipsis"><span class="invisible">\xa0</span></span></a><a class="twitter-timeline-link u-hidden" data-pre-embedded="true" dir="ltr" href="https://t.co/Qr4LM3uTxA">pic.twitter.com/Qr4LM3uTxA</a></p>', 'timestamp': '2020-07-14T03:02:09', 'timestamp_epochs': 1594695729, 'tweet_id': '1282872986467397633', 'tweet_url': '/slam_hub/status/1282872986467397633', 'user_id': '1244129482132209664', 'username': 'SLAM-Hub', 'video_url': ''}
今回使うのは主に以下の3つになります。
- text:ツイートの本文
- link:ツイートに紐付けられたメディアのURL(Youtube, Aixivなど)
- img_url:ツイートに直接貼り付けられた画像のURL
ここから,スライド形式の資料のタイトル,本文,説明画像を1セットにして資料を集めていくというのが今回の流れです。
コンテンツ作成
先程抽出したデータからサーベイ資料に載せるコンテンツを作成していきます。
- タイトル≒論文題目
- テキスト≒ツイッターの説明テキスト
- サムネ画像≒代表的な画像
の3つが必要と考えます。
arxivの論文情報をスクレイピング
最も多いリンクはarxivのURLです。ここからタイトルを抽出します。
PythonでarXiv APIを使って論文情報取得、PDFダウンロード | note.nkmk.me
str形式で与えられるarxivid(例:"110.680”)を抽出すれば以下のようにタイトルを得られます。
import arxiv # get arxiv title arxiv.query(id_list=[arxivid])[0]["title"]
linkのURLからIDを抽出します。
- スラッシュでsplitして後ろを抽出
.pdfが混じっている場合があるので非数字を除去- 番号の最後に英字が入る場合があるので先頭だけを見て判断
# .pdfが混じっている時がある。数字だけを抽出するようにする。 arxivid_ = 'https://arxiv.org/abs/1910.14139.pdf'.split('/')[-1] ids = [s for s in arxivid_.split('.') if s[0].isdigit()] arxivid__="" for i in range(len(ids)): arxivid__ += ids[i]+"." arxivid = arxivid__[:-1]
途中の数値部分のみを抜き出すロジックは以下のサイトを参考にしました。 regex - How to extract numbers from a string in Python? - Stack Overflow
Youtubeをスクレイピング
同様に多いlinkはyoutubeのリンクです。ここからはサムネイル画像とタイトルを抽出します。
Youtubeにアクセスして情報を抜き出すのは以前APIを取得してやっていましたが,APIの管理は正直面倒です。
今回は以下に示すyoutube-dlというAPIなしで使えるコマンドラインツールを用います。
導入はpipで問題なく入れられます。
pip install youtube-dl
コマンドラインツールなので,subprocess.check_outputを用いてコマンドライン出力を取得します。
import subprocess imgurl = subprocess.check_output("youtube-dl --get-thumbnail \""+URL +"\"", shell=True) title = subprocess.check_output("youtube-dl --get-title \""+ URL +"\"", shell=True)
帰ってくるURLの文字列には時々特殊文字が入っているのでエスケープが必要です。
まとめコード
- 辞書型の要素を格納するリストを作る。
- タイトル,本文,画像URLをそれぞれ加えて行く。
例外で画像だけがある場合もあったのでその時はタイトルは適当にして処理しました。
長いので詳細をクリックして見てください。
import arxiv import subprocess docdics = [] for dics in sdic: ddic = {} title = "" imgurl = "" if dics['links']:# if has link # linkの最後尾をタイトルにする title = dics['links'][0].split('/')[-1] # Youtubeだった場合 if 'youtu' in dics['links'][0]: # if it is youtube link imgurl = subprocess.check_output("youtube-dl --get-thumbnail \""+dics['links'][0] +"\"", shell=True) title = subprocess.check_output("youtube-dl --get-title \""+ dics['links'][0] +"\"", shell=True) # Arxivだった場合 if 'arxiv' in dics['links'][0]: arxivid_ = dics['links'][0].split('/')[-1] ids = [s for s in arxivid_.split('.') if s.isdigit()] arxivid__="" for i in range(len(ids)): arxivid__ += ids[i]+"." arxivid = arxivid__[:-1] title = arxiv.query(id_list=[arxivid])[0]['title'] if dics['img_urls']: imgurl = dics['img_urls'][0] # linkはないけど画像はある時 elif dics['img_urls']: imgurl = dics['img_urls'][0] title = "image only" ddic['id'] = dics['tweet_id'] ddic['title'] = title ddic['imgurl'] = imgurl ddic['text'] = dics['text'] docdics.append(ddic)
データ後処理
ここからはヒューリスティックな処理が続きます。
- 広報ツイートなどをフィルタリングする
- youtube-dlが返す文字がbyte文字列なので補正する(最初からやってればよかった)
広報ツイートをフィルタリングする
LinkのURLがあったとしても必ずしもサーベイ紹介Tweetとは限りません。(そらそうだ) 広報ツイートなどと区別するために,特定のキーワードを含んでいるかどうかでフィルタリングします。
# 広報ツイートが紛れ込んでいる。URLか本文のキーワードで落とすか。"可能","提案","実現"などのワードのどれかがはいっていないなら弾く。 filterwords = ["可能","提案","実現","推定","定式","最適化","生成","評価"] for docs in docdics: if not any(wd in docs["text"] for wd in filterwords): print(docs["text"])# テキスト閲覧
byte文字列をstrに変換
これは完全に私個人のミスですが,youtube-dlで得られる文字列がbyte文字列なのでこれをstrにデコードします。
# Encode to utf8 # string byteの混じった文字をstringに統一する # type(b'abcd') == bytes を用いる for docs in docdics: for dd in docs: if type(docs[dd]) == bytes: # .decode()でデコード
まとめコード
他にも, - タイトルの文字列に改行コードがあったのでスペースに変換
などの処理を行いました。
## filtering
filterwords = ["可能","提案","実現","推定","定式","最適化","生成","評価"]
filtereddics=[]
for docs in docdics:
if any(wd in docs["text"] for wd in filterwords):
fdocs = docs
# decode bytes
for dd in fdocs:
if type(fdocs[dd]) == bytes:
fdocs[dd]=fdocs[dd].decode()
# Remove \n from title
fdocs["title"] = fdocs["title"].replace("\n"," ",10)
filtereddics.append(fdocs)
.mdファイルに書き込み
markdown形式で最終的にまとめますがせっかくなのでMarp for vscodeで表示できるスライド形式に変換します。
- 改行してスライド区切り
---を入力 - タイトル,本文を入力
- 画像を右端40%のfit形式で挿入
これを実行するコマンドは,
mkdocfile = open("survey.md","w+",encoding='utf-8') for mkdics in filtereddics: imgurl=mkdics["imgurl"] if imgurl: if imgurl[-1] == "\n": imgurl = imgurl[:-1] onepagestring = "\n---\n"+"## " + mkdics["title"]\ + "\n" + mkdics["text"]\ + "\n \n" mkdocfile.write(onepagestring) mkdocfile.close()
以上!
Marpに落とし込む際は以下の記述を文頭に置きます。
--- marp: true header: 'from @slam_hub' size: 16:9 paginate: true ---

TODO・改善点
- 権限とかの問題(なぜ記事を先に書いた)
- Twitterのスクレイピング力不足でネストになっているツイートの追加情報を取得できていない
- タイトルに改行文字が含まれているので省く。
- サーベイツイート判定法がヒューリスティックに寄りすぎている
- キーワードごとに論文を分類したい。自然言語処理的なことをする?
ご意見・感想お待ちしております。
追記:Twintを用いた解析
次の記事でTwintを用いたTweet取得を試した所,結構上手く行ったのでDockerを用いた解析でも作成してみました。 Docker image形式なので環境を問わず実行できると思います。(所要時間10分くらい?)
参考記事:
TwitterScraperを使ってTweet情報を収集する
概要
- Twitter APIを申請しなくても使えるTweetScraperを使う
- pipのインストールにハマったのでDockerでビルドする
- キーワードやユーザなどで検索できるが,一部取得できないTweetもある?
注意:Twitter社はAPIを通さないスクレイピングを禁止しているようなので本記事の手法は近いウチに使えなくなるかもしれません。 TwitterScraperを使ってスクレイピングできるのでは - Qiita
追記:対抗ツールtwintについて
似たようなツールとしてTwintというものもありました。
TwitterScraperと違って自己言及しているツイートも収集できるのでこちらを使ったほうが良さそうです。
追記2:
これを活用して作ったのが以下の記事です。
背景
有用なTweetをしている人のTweet内容をスクレイピングしてデータベース化したい。そんなときがあります。
スクレイピングに使えるTwitter APIは申請時に結構面倒な作文を要求されるので面倒な作業のいらないものを探していた所,Twitterscraperというものを見つけました。
煩雑な作文(英語)を求められるTwitter APIを介さずともTweetを取得できるようなのでこちらを使ったスクレイピングをやっていきたいと思います。
pip install twittercraperでインストールできるようですが,
自分の散らかったPython環境だと上手く行かなかったのと,Python環境がPC毎に違うのでDockerでやることにしました。
非常に紛らわしいのですがTwieetScraperというのもあるようです。どっちが優れているのかおいおい確認したいと思います。
DockerでのBuild
Cloneしたディレクトリに移動後,
docker build -t twitterscraper:build .
でビルドします。が,私がやったときは下記のようなエラーがでました。
Please make sure the libxml2 and libxslt development packages are installed.
依存関係が上手くいってないのでここを見て DockerfileをFixします。
変更したDockerfile詳細
FROM python:3.7-alpine
COPY . /app
WORKDIR /app
RUN apk add --no-cache \
gcc \
libc-dev \
libxml2-dev \
libxslt-dev
RUN python setup.py install
CMD ["twitterscraper"]
環境にも寄りますがCorei5-3000番台の古いPCではビルドに2~3分かかりました。
使い方
今の所更新されていませんが公式の使い方ではにあるコマンドを実行してもファイルが生成されませんでした。
自分の環境では以下のように実行しました。
docker run --rm -it -v <PATH_TO_SOME_SHARED_FOLDER_FOR_RESULTS>:/app twitterscraper:build <YOUR_QUERY>
上から軽く説明すると
- dockerを起動して
- <PATH_TO_SOME_SHARED_FOLDER_FOR_RESULTS>:に適当なディレクトリを直接表記で指定してDocker側の
/appと関連付けた後に, - <YOUR_QUERY>に示す適当な検索コマンドを実行しコンテナを終了
となります。
2つ目の工程を経ることでDocker環境内で作成したファイルをホストのディレクトリ内に生成することが出来ます。
【Docker】Dockerでホストのディレクトリをマウントする - Qiita
- ヘルプを見る
docker run --rm -it twitterscraper:build twitterscraper --help
特定のユーザのTweetをスクレイピング
試しによくサーベイ情報を載せてくれているslam_hubさんのTweetをスクレイピングしてみましょう。
特定のユーザのTweetを抜き出すには--userオプションを用いる手法とfrom:<USERNAME>のクエリを指定する2通りの方法がありました。
得られるデータに若干の違いがありましたが,取得したTweetの総数は前者のほうが多かったので前者をおすすめします。
--userオプションを用いる手法
docker run --rm -it -v /home/yoshi/Documents/GitHub/MyMemo/src/Twitter:/app twitterscraper:build twitterscraper slam_hub --user -o slamhub.json --lang ja -l 1200
from:<USERNAME>オプションを用いる手法
docker run --rm -it -v /home/yoshi/Documents/GitHub/MyMemo/src/Twitter:/app twitterscraper:build twitterscraper "from:slam_hub" -o slamhub2.json --lang ja -l 2000
出来たこと,出来なかったこと
得られたTweetの中身をざっと見ると,テキストだけでなく,ユーザ反応やリンクの有無など細かな情報が得られていることがわかります。
サーベイ記事だけ抜き出したかったのでリンクの有無やちょっとしたキーワードから結果を絞れそうですね。 後でMarkdownなどを介して読み物形式にまとめたいと思います。
{'has_media': True, 'hashtags': [], 'img_urls': ['https://pbs.twimg.com/media/Ec2t_Y-UcAAYEyM.png'], 'is_replied': True, 'is_reply_to': False, 'likes': 26, 'links': ['https://arxiv.org/abs/2004.01793'], 'parent_tweet_id': '', 'replies': 1, 'reply_to_users': [], 'retweets': 9, 'screen_name': 'slam_hub', 'text': '画像からの物体方向推定を,self-supervisedに学習する枠組みを提案.画像から3次元方向とスタイル特徴量を抽出し,それらの潜在変数を元に幾何学的変換を行うGenerator(GAN)を用いて学習.損失には一貫性と水平対称性を利用し,教師あり学習に匹敵する性能を達成.\nhttps://arxiv.org/abs/2004.01793\xa0pic.twitter.com/Qr4LM3uTxA', 'text_html': '<p class="TweetTextSize TweetTextSize--normal js-tweet-text tweet-text" data-aria-label-part="0" lang="ja">画像からの物体方向推定を,self-supervisedに学習する枠組みを提案.画像から3次元方向とスタイル特徴量を抽出し,それらの潜在変数を元に幾何学的変換を行うGenerator(GAN)を用いて学習.損失には一貫性と水平対称性を利用し,教師あり学習に匹敵する性能を達成.\n<a class="twitter-timeline-link" data-expanded-url="https://arxiv.org/abs/2004.01793" dir="ltr" href="https://t.co/rEGIDLI41f" rel="nofollow noopener" target="_blank" title="https://arxiv.org/abs/2004.01793"><span class="tco-ellipsis"></span><span class="invisible">https://</span><span class="js-display-url">arxiv.org/abs/2004.01793</span><span class="invisible"></span><span class="tco-ellipsis"><span class="invisible">\xa0</span></span></a><a class="twitter-timeline-link u-hidden" data-pre-embedded="true" dir="ltr" href="https://t.co/Qr4LM3uTxA">pic.twitter.com/Qr4LM3uTxA</a></p>', 'timestamp': '2020-07-14T03:02:09', 'timestamp_epochs': 1594695729, 'tweet_id': '1282872986467397633', 'tweet_url': '/slam_hub/status/1282872986467397633', 'user_id': '1244129482132209664', 'username': 'SLAM-Hub', 'video_url': ''}
一方,確認した問題として自分へのリプライ形式で綴られる連投タイプの子Tweetを取得できないというのがあり,有用な情報をいくつもLostしていることが判明しました。 他の方の環境で再現するかは不明ですが余裕があればそのへんも調査していきたいと思います。
TODO
ブラウザで動くFaceVTuberを使ってバーチャルYotuberの皮を被ってZoomに参加する方法
はいどーも!キズナアイです!

今日は私の皮を被って会議に参加する方法について紹介していきます。 ブラウザで動くので導入は~15分です!
FaceVTuberを使ってバーチャル美少女モデルを動かすよ!
PCのカメラから中の人の表情を取得してバーチャル美少女モデルを動かすサイトがあります。
基本的な使い方
初回接続時には,デバイス(すなわちPCのWebカメラ)へのアクセスを許可するように言われるよ!
見逃した場合はURLの右側にあるボタンから改めて許可やビデオ入力を選択できます。

これを踏まえて,手順は
- [Start]を押してカメラのアクセスを許可する。
- 前を向いて[Set]を押す。(顔がずれたときなどはもう一度Setを押すと前向きに戻る)
- 右側のウインドウのアバターが顔に合わせて動く!
となります。これが出来た時以下の様になっていると思うよ!(顔は隠しました)

このままだと表示が小さいからここから[Pop Window]を押すことで大画面に映すことができます。
好きなアバターのモデルをDLして当てはめよう!
スクロールするとFaceVTuberに対応しているモデル一覧があるよ!

好きなアバターをDLしよう。キズナアイになりたい人はこちら。
zipファイルをDLしたら,アバター下の「ファイル選択」からDLしたzipファイルを指定しよう!
規約が読み込まれるらしく,上の方でたくさんOKを押す必要があるけどそれが終われば完成!

OBS StudioとOBS Virtual camを使って 出力しよう!
さっきのキズナアイをZOOMに映します!
ZOOMの会議で先程のモデルを使うにはキャプチャしたビデオをビデオ出力として認識して貰う必要があります。 作者は意欲的な方なのでひょっとしたらこの先機能として実装されるかもしれませんが,ひとまず自分はOBS Studioを経由してやりました。
www.slideshare.net
必要なソフトをDL!
以下をぽちぽちDLしてください!
OBS Studioを起動して,「ツール」→「Virtual Cam」が表示されていればOK!
OBS StudioからFaceVtuber のウィンドウをキャプチャ
- 左下の「ソース」の箇所で「+」を押してウィンドウキャプチャを選択。
適当に名前をつけてOKを押します。

すると Windowの選択画面に行くので先程ポップアップさせた画面を選択します。

すると以下のように表示されるはず。(2画面になってるのは「スタジオモード」をうっかりおしちゃったのでスルーしてください。)

このままだと,ブラウザの上とか下のスクロールバーなども写っちゃうのでサイズや場所を調整してトリミングします。

トリミング結果を反映するには右下の「スタジオモード」をぽちぽちしてください。(詳しくないのでもっといい方法あったらすみません)
Virtual Camでビデオ出力!
キャプチャした「私」をビデオ出力しましょう!
「ツール」→「Virtual Cam」を起動し「Start」を押すだけです。
私の設定はこれ。

するとビデオ出力に「OBS-Camera」という項目が出るのでZoomなどのツールでInputに「OBS-Camera」を選択しておしまい!
完成?

Tips
- FaceVtuber は非アクティブの時はリソースをもらえないのか非常に動作が遅くなるので,Zoom中は他のタブより前面に出しておくと良いです。
TODO
- 背景を設定する
- バ声を設定する?
課題
- メガネをつけると顔を認識しにくい
- 目が細くて?表情があまり読まれない
顔のパーツ検出ががOpenCV標準っぽい挙動なので認識の箇所を変えればもっと快適な表情検出になるかも!
Atcoder173反省会(Bit全探索,strからchar変換,etc)
Python使用者です。慣れたらC++の訓練所としても用いたいなぁと思ってます,
Atcoder173所感
- 数え方にまつわる問題が多い?A~Dを解いた。
- C:全探索
- D:中学入試っぽいパズル問題
20分遅れで始めたがギリギリ4問解けた。E,Fが時間内に解ける日は遠そう…
各設問の反省や学習事項
C:Bit全探索
maskを作成してnumpyで行列のAndを*演算子で取る手法を思いついた。OpenCV脳である。
自分的には初めてBit全探索を行った。正攻法ならitertoolsを使うらしい。
Pythonでお手軽にbit全探索を行う方法【itertoolsを使おう!】 | プログラミングの教科書
itertools.product( “候補となるオブジェクトの集合”, “選ぶ回数” )で書けるため以下のように簡単にできる。
print(list(itertools.product([0,1], repeat=2))) #[(0, 0), (0, 1), (1, 0), (1, 1)]
今回,itertools.product([0,1], repeat=W)などと書けば簡単にBit演算表が作れていた。
2進数変換を用いたBit全探索
試験中はググる前に自分で書けそうなので自分で書いた。(時間がかかった)
大枠としては以下の通り。
for h in range(2 ** H): for w in range(2 ** W): # 各要素1 or 0 のiteratorリストを作る … #ループさせる関数 …
iterのリストの作り方
hやwが特定の値の時にその値をH桁,W桁の2進数表記リストにしたかった。
hが3,Hが4の時
[0,1,1,1]のような出力が欲しい。
用いた要素は以下の3つ。
bin():2進数表記へ変換する関数。0b~~のstrで値を出してくる。zfill(n):strの先頭をn桁になるまで'0'で埋めてくれる関数- split:
'10010'みたいなstrを数のリスト[1, 0, 0, 1, 0]に変換する自作関数
まず,文字列を得るには:
# 7を4桁の2進数にする。binの後ろ二桁を抜き出して桁数に会うように0でfill w0b = bin(7)[2:].zfill(4)
その後,
# splitは予約されていることが多いので関数名は別にするのが良い。 def split(word): return [int(char) for char in word] # we got [0,1,1,1] split(w0b)
余談:Str から Charの変換で沼った
for文で抜き出すか,iterで一個一個読むか? 後で考える。
D
ひらめき問題だったので今のとこ特に書くことなし。
.sort()は元の関数の順序を変えるので使わない- sortは基本昇順だが
sorted(A, reverse=True)のように書けば降順になる - 復習:ソートの計算量はNlogN