概要
- Splatoon2の録画の動画からカウントや時間,スペシャルなどの情報を抽出するためにOCRを行う
- コンテンツ
- TesseraactとjTessBoxEditorを用いてSplatoon2のフォントを学習
- pyocrを用いて画像から文字領域を抽出の上,OpenCVを用いて下処理・描画
背景
突然ですがIkaLogというツールを皆さんご存知でしょうか。 詳細は下記のスライドに任せますが,Splatoon1の時にプレイ画面を解析して試合の詳細な流れを記録するツールです。
www.slideshare.net
具体的には,ステージ名などの基本情報から敵味方の生存状況のタイムライン,スペシャルやカウントの進みなど多岐にわたる解析が可能だったようです。
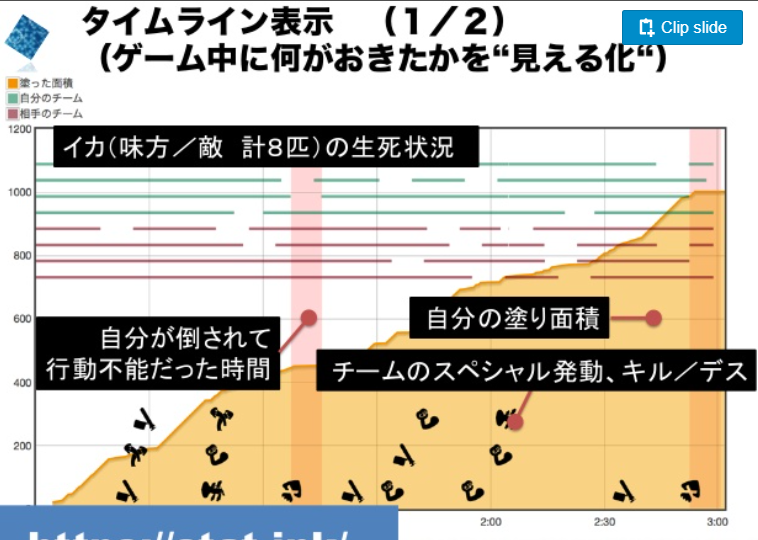
自分もスプラプレーヤーとして試合の流れなどの情報を一度整理したいと思い今回のツールを個人開発してみようと思い立つに至りました。
目指すところ
筆者の開発環境
参考までに筆者の開発環境を載せます。言語はPythonで重要なパッケージは以下のとおりです。
- Windows10 Home, Python3.6 in Anaconda
- OpenCV 3.4
- Tesseract 5.0 alpha
- pyocr 0.7.2
の上で動かすことを前提にしています(古くてごめん)。
OCR環境を整えてSplatoon2のフォントを学習する
本章ではまず,環境を整えてSplatoon2のフォントを学習するところからやっていきます。
ここでは下記の記事が大変参考になるので是非一読をおすすめします。というか細かい部分は下記を参照してください。
TesseractとPyOCR環境のインストール
Python上で学習を動かせるように環境を設定します。詳しくはこちらに任せるとして勘所だけ書いておきます。
インストール確認には下記のコマンドを実行してください。
import pyocr tools = pyocr.get_available_tools() for tool in tools: print(tool.get_name())
出力にTesseract (sh)が入っていれば成功です。
学習用ツールjTessBoxEditorのインストール
次に,フォントを新たにTesseractに学習させる時に使えるGUIツールをインストールします。
- JRE8.0以降の実行環境をインストール(インストール参考)
- ここでも環境変数を設定するので再起動しといたほうが無難
- jTessBoxEditorをDLしてくる
- DL後回答したフォルダで
java -Xms128m -Xmx1024m -jar jTessBoxEditor.jarを実行
- DL後回答したフォルダで
成功すれば下記のような画面が出てくるはずです。(画像出典: https://www.tdi.co.jp/miso/tesseract-ocr)
Splatoon2のフォントをDLしてくる
Tesseractに新たに文字を学習させるには文字のフォントが必要なのですがSplatoon2は任天堂オリジナルフォントで2次配布されていません。
フォントの製作は最も苦労するパートのハズですが,ここでは海外有志が作成したと思われるSplatフォントを用います。
インストールするにはDLしたttfファイルをC:\Windows\Fonts\にコピーします。
(上記フォルダにないとjTessBoxEditorが認識しなかったため。)

Splatoon2のフォントを学習する
- 学習用フォントファイルの作成
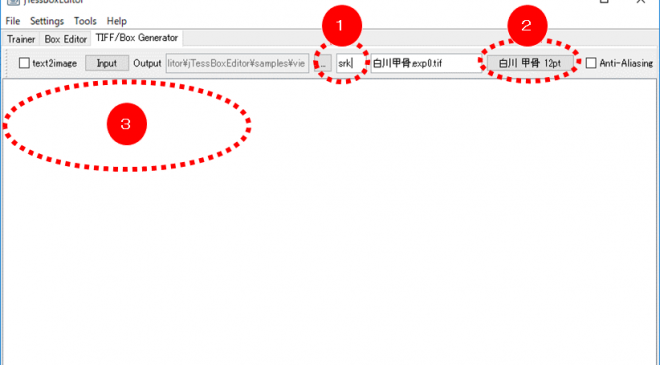
- iTessBoxEditorを起動し、「TIFF/Box Generator 」タブを開く。
- 上図(1)に学習済み言語を表す英字を入力。(これは後で言語として選択する時に使うもので自分で決めます。三文字を使うことが多いですが今回は「spl2」としておきます。)
- 上段の位置から「Splatフォント」を指定
- 学習したい文字を打ち込む。(打ち込んだ文字のみを学習する仕様のようです。下図では数値だけを学習する例を見せています。)
- Generateを押してboxファイルを作成する。

上記をすべて実行すると下記のようなファイル群が生成されるので後の工程のために任意のフォルダに移動すると良いです。
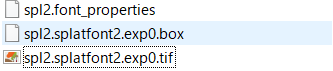
今回は数値のみを学習したsplというboxファイル,カタカナ文字を学習するspl2というboxファイルを作成しました。
カタカナの学習の五十音は下記のサイトからコピペしてきました。(本来は頻出の単語なども学習するっぽい(要検証)なので,スプラ2で使われる文字列などを学習したほうが良さそうです。)
学習の実行
こちらも上記文献の引用です。
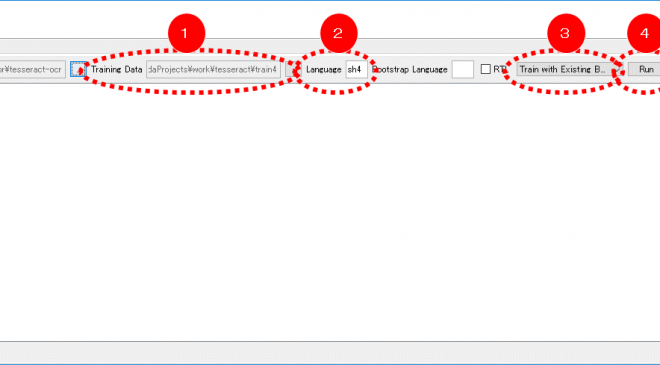
- iTessBoxEditorでの学習の実行。まず「 Trainer 」タブを開く
- Traininig Data(1):上記で生成したファイル「spl2.splatfont2.exp0.box」を選択。
- Language(2):「spl2」と入力。
- Training Mode(3):「Train with Existing Box」を選択。
- Run(4)を実行し,
** Moving generated traineddata file to tessdata folder ** (改行) ** Training Completed **のメッセージが出たら完了。
- 生成されたファイル
spl2.traineddataをTesseractの環境にコピー。- 自分の場合は,Programfiles以下の
C:\Program Files\Tesseract-OCR\tessdataに環境が合ったのでそこにコピー。
- 自分の場合は,Programfiles以下の
ここまでで完了。
結果だけ欲しい人用
上記の経緯は結局,「Tesseraactで使えるスプラトゥーンの文字フォント学習ファイルを生成」しているだけなので端的に結果のファイルをDLしてコピーできれば良いです。
とりあえず私が雑に作ったものを以下に載せます。
Splatoon2のカタカナを学習したフォントファイル。(Tesseract用)spl.train…
参考までに,似たようなことをやっている方として下記のような記事があります。
OpenCVとPILを用いてOCR結果を表示
Pythonのpyocrモジュールを用いてOCR結果を取得して図示するところまでやります。
image_to_stringという関数を用いるのですが大体下記2つについて書きます。
PyOCRのimage_to_stringでOCRする
とりあえず初めて使うパッケージは公式ドキュメントを見よというのが鉄則なんですが全然検索の上位に出てこないので結構キレそうになります。
一応まともそうなのは下記でしょうか。
また,下記の記事なども参考にしました。
私が使った関数は
tool.image_to_string( <PIL image>, lang="spl2",builder=pyocr.WordBoxBuilder())
というものです。
引数についての説明は以下の通り。
- tool:pyocr.get_available_tools()にリストで入っている一要素。今回は
tool = pyocr.get_available_tools()[0]でOK。 - Image :cv2(numpy)の画像ではなくてPILのImage形式で入れる
- lang:使用する検出言語。日本語なら”jpn”,英語なら”eng”,今回はカタカナを認識するので先程学習した”spl2”を用いる
- builder:どのような出力を吐き出すかを変更できる。今回は位置と単語と確信度を抽出できる
pyocr.WordBoxBuilder()を使用。
特にPILのImage形式で入れなければ行けないのがだるいためcv2とPILとの変換関数を用意する必要があります。
ということで変換を含めた関数ファイルは下記の通り。
import pyocr import cv2 import numpy as np import pyocr.builders import matplotlib.pyplot as plt from PIL import Image, ImageDraw, ImageFont def cv2pil(image): ''' OpenCV型 -> PIL型 ''' new_image = image.copy() if new_image.ndim == 2: # モノクロ pass elif new_image.shape[2] == 3: # カラー new_image = cv2.cvtColor(new_image, cv2.COLOR_BGR2RGB) elif new_image.shape[2] == 4: # 透過 new_image = cv2.cvtColor(new_image, cv2.COLOR_BGRA2RGBA) new_image = Image.fromarray(new_image) return new_image def extract_imageboxes(img,lang_setting="jpn",tool = tool, builder = pyocr.builders.WordBoxBuilder(),): """ img: opencv img lang: language setting builder """ LineBoxes = tool.image_to_string(cv2pil(img),lang_setting, builder = builder) res = {} for lb in LineBoxes: dic = {} dic["position"] = lb.position dic["confidence"] = lb.confidence res[lb.content] = dic return res
返り値として,検出した文字列をKeyにした辞書型オブジェクトの辞書を返します。 使用例は後ほど。
PyOCRの検出結果を描画する
PyOCRで検出した結果,「テキスト」,「BoundingBox」,「確信度」が帰ってくるのでこれを可視化します。
具体的には下記の画像のようにします。
- 日本語テキストを書き込む
- BoundingBoxを書き込む
- 確信度によって色を変える

OpenCV画像に日本語テキストを書き込む
簡単のように見えて一番だるい作業でした。下記の記事を改変して作業しています。
下記改良版においては一度画像をPILに変換してからPILの関数を用いて書き込んでいます。
これらの機能のまとめ
以上の
- extract_imageboxes:OCR情報抽出
- cv2_putJPText:日本語書き込み関数
の2つと色変換の関数を加えて画像を直接加工するshowWordBoxesAndText関数を作りました。
def hsv_to_rgb(h, s, v): bgr = cv2.cvtColor(np.array([[[h, s, v]]], dtype=np.uint8), cv2.COLOR_HSV2BGR)[0][0] return (int(bgr[2]), int(bgr[1]), int(bgr[0])) def showWordBoxesAndText(img,showimg=None,lang_setting = "jpn"): """ opencv画像を元にpyocrで読んだテキストをBoundingBoxと一緒に書き込む。赤味が強いほど確信度が高い。 """ imgshow = img.copy() if showimg is None else showimg.copy() dics = extract_imageboxes(img,lang_setting) print(dics) # 一応結果が見たいのでShowしている #fontpath ='C:\Windows\Fonts\MEIRYOB.TTC' # メイリオを指定する場合。Windows10 だと C:\Windows\Fonts\ 以下にフォントがあります。 for dic in list(dics.keys()): if len(imgshow.shape) == 2: fontcolor = int(2.55 * dics[dic]["confidence"]) else:# color image fontcolor = hsv_to_rgb(2 * dics[dic]["confidence"],255,255) text = dic cv2.rectangle(imgshow, dics[dic]["position"][0], dics[dic]["position"][1], fontcolor) cv2_putJPText(imgshow,text ,dics[dic]["position"][0],fontScale=15,color= fontcolor,mode=1) return imgshow
その他コツ
いくつかのサンプルを試した結果下記のようなことが言えそうです。
- 大きな画像ほど文章抽出が困難になるのでなるべく読みたい文字に対して領域を小さく区切って検出する
- 文字が白いなどの付加情報があるなら事前に色や輝度でマスクすると捗る
- 確信度(Confidence)でフィルタリングするのは雑音除去に有用だが稀に
半角スペースが高い信頼度で検出されるので弾く必要がある- 具体例:
{' ': {'position': ((0, 0), (0, 151)), 'confidence': 95}}みたいなかんじ。
- 具体例:
他にも傾向などありましたら聞きたいです。
適用結果とその比較
ということで,上記の関数を使って抽出してみました。 比較として,デフォルトでDLできる日本語検出”jpn”と今回学習したスプラトゥーン2のカタカナフォント”spl2”を指定した際の違いをお見せします。
スペシャル情報
まず,スペシャルの文字列を検出したときですが,
| デフォルトの”jpn”で検出した結果 | 学習した”spl2”で検出した結果 |
|---|---|
 |
|
このように完璧ではないですが欲しい情報に近いものが得られました。(実際スペシャルを知りたいだけなのでこれくらいならその他文字列との距離を取れば余裕で分類できそうです。)
試合時間・カウント
試合時間は中央の固定領域にあるので領域指定して抜き出せば簡単に呼べます。 この数値に限って言えば,別に英語のOCRでも正しく検出出来ました。
| デフォルトの”jpn”で検出した結果 | 学習した”spl”で検出した結果("eng"でも同様の結果) |
|---|---|
 |
 |
一方でカウントは簡単かと思いきや,下記のように広い領域では何も検出できませんでした。

白い領域を抽出後,下記程度に範囲を絞って下の画像のレベルまで情報を整理してようやく正しく検出が出来たのでそのあたりはちょっと調整が必要そうです。

ルール名・タイトル
ルール名も精度が悪いです。これは比較的簡単な理由で,ルールのフォントは学習したフォントとは若干違うからです。 この辺を改善しようとすると学習器のチューニングが必要ですが,4つのルールを分類出来さえすればいいのでうまいこと距離を導入できればなんとかできそうです。
| デフォルトの”jpn”で検出した結果 | 学習した”spl”で検出した結果("eng"でも同様の結果) |
|---|---|
 |
 |
おわりに
ということで,PyOCRとTesseractを用いてスプラトゥーン2の画面情報を読み取ろうという記事でした。
本当はアドベントカレンダーに載せようと思っていたのですがあまりにも諸エラーや記事の執筆に時間がかかってしまったため遅刻&中途半端な記事になりました。すいません。
他にもスプラ愛好家として以前,Splathon2で散々言われている編成などの「勝ちにつながる要素」を定量的に解析しようというのをやっていたりして,今中途半端になっているのでそちらもうまいこと計画して進めて行きたい所存です。
TODO
やりたいことはあるのですが1月は結構仕事が忙しそうなのでしばらくまた休眠するかもしれません…
- 一連のコードを整理して公開
- 記事のブラッシュアップ
- 検出した結果を元に動画から一通り情報を抜いてみる
- 適切な距離を定義して検出単語を分類
- 前処理とかも含めたコードの整理
- 頻出な単語を学習することで検出精度の向上?
- プロジェクトを進める
超余談:Gistにバイナリを上げる方法
バイナリはドラッグアンドドロップ出来ないので無理だと思っていたがどうやら下記の方法で普通にアップできます。結構面倒ですがまぁヨシとします。
- 適当なGistを建てる
- URLをコピってClone
- バイナリを追加・リポジトリ修正してPush