m1 mac 環境構築メモ① 入力の設定やRemap、基本操作など
3月末にM1 macを買ってウキウキだったものの、なんだかんだWSL2にハマってしまって放置していました。 とりあえずまともにタイピングできる環境を整えたのでメモします。
機体と環境について
- 2021年度版 m1 macbook air
- 16GB, 512GB SSD
- JIS配列キーボード
 - シルバー")
電池の持ちが一昔前のガラケーレベルなのが最も顕著に恩恵を感じます。 今はGoogle Colabなどで作業環境共同化もできるので回線さえあれば外出時でもそれなりに色々できます。
記事内での設定内容
- Terminalをショートカットで開くようにする
- キーボード設定
- ファンクションキーをFnなしで動かす
- JISキーボードをUS入力風に変更する
- 単語移動を変更
- 装飾キーまわりのメモ
ターミナルをショートカットで開く。
⌘スペースでWin+rのように呼び出しメニューを出せるのでそこでターミナルとうてばデフォルトでもキーボードだけでターミナルを起動できます。
ただ、やっぱCtrl+Alt+T的なので一発で開きたい場合はちょっと回り道をする必要があります。
Automatorというアプリでサービスというのを作成してそれにショートカットを割り振るというのがよく使われているようです。
https://ry0.github.io/blog/2015/10/21/open-terminal-shortcut/#gsc.tab=0
コンフリクトがない限りいくつでもショートカットは設定できます。
まっさらな環境だと普通にcontrol+command+Tを割り振れました。
キーボード設定
基本的なところ
基本的なところは箇条書きにて失礼します。
- capslock -> command
- keyboardの修飾から
- タップしてクリック
- トラックパッドから設定
- Enter一回で入力を確定するなどとか設定
- キーボード入力ソースからWindows風とする
- https://bl6.jp/dev/computer/shortcut-key-switch-desktop/
- FunctionキーをFnなしで起動する。
KarabinerでJISキーボードをUSキーボードに設定
下記の記事の通りにKarabinerをインストールします。
https://qiita.com/canonrock16/items/0c090276b2f1fd8eb0ab
初回はキーボードの識別に時間を取られてちょっとビビります。 その後、権限を求められるのでそのあたりをきちんと設定したらOKです。

私の設定は以下の通り。
| 変換前 | JISの該当キー | 変換後 | USの該当キー |
|---|---|---|---|
| international1 | ろ | grave_accent_and_tilde(`) | ‘ |
| international3 | ¥ | backslash | \ |
| caps_lock | 左下の奴 | left_command | 左⌘ |
| right_command | 右⌘ | right_control | 右^ |
右のシフトも使わない気がしているので適当に変換しようかなとは思っています。
Karabinerでその他ショートカット作成
Karabinerでは複数キーの組み合わせもRemapすることができます。
これはComplex modificationsという箇所から設定できインターネット上からインポートしてくることができます。
https://ke-complex-modifications.pqrs.org/?q=option%20%2B%20arrows
例えばWindowsでやっていた操作を一通りMacで動かせるようにするには下記の設定検索からWindows shortcuts on macOS
というのを検索してImportすれば良いです。
自分の場合単語移動をcontrolでできるように下記を入れました。
Exchange control + arrows keys with option + arrows keys
装飾キーまわり
Macを使うにあたりちょっと混乱したのがWindowsであったCtrl/Alt/Winキーの挙動がMacではあまり対応していないことです。
⌘はAltとCtrlの機能を兼ねたような挙動を持っていますが肝心なときにどっちかわからなかったりします。
Pythonを雑に起動して終了しようと思ったら画面分割されたりとか、Chromeで新規タブは⌘Tで出すのにタブ移動は^Tabだったりするのでちょっと困ります。
単語移動関連
WindowsやLinudxではCtrlで単語移動できますが、macではOptionで移動する必要があります。(自分はKarabinerの設定で変更しました。)
とりあえずデフォルトでのvscodeでの挙動を下記メモします。
| option | 上下 | 行を保持して移動 |
| option | 左右 | 単語移動 |
| command | 左右 | 行頭行末移動 |
| command | 上下 | 文頭文末移動 |
| control | 左右 | ワークスペース切り替え |
| control | 上 | ウィンドウ選択 |
| control | 下 | 最近開いたファイル表示? |
使いにくいと思った部分は混乱がない範囲でRemapして行けばいいと思います。
また、日本語の単語移動を実現するにはその都度設定が必要のようです。 VScodeの場合はJapanese Word Handerを入れれば良さそうでした。
スクリーンショット
スクリーンショット自分の場合、ファイルに保存する必要はなくてクリップボードに入れば良いことが多いです。 下記を参考にしました。
https://tamoc.com/mac-screenshot-window/#i-3
結論、特定領域・Windowをクリップボードにコピーするには下記のとおりやればいいです。
- control ⌃+command ⌘+shift ⇧+4 で自由領域Cropを起動
- Spaceを押してWindowの選択をする
controlを押さなければ普通にデスクトップに保存されるようです。
その他
プログラム関係 - ターミナルの名前を変更 - https://code-graffiti.com/how-to-change-the-prompt-display-on-the-mac-terminal/ - Xcodeをインストール - homebrewのインストール - VSCODE - https://stackoverflow.com/questions/30065227/run-open-vscode-from-mac-terminal
今後もなにかあれば追加していくと思います。
2021年4月のよかったもの
誘われたので。4月は特になにかしてないのであまり書くことはありません。 (以下からである調)
まんてん鮨
下記の記事にも紹介されている「まんてん鮨」の日暮里店に食べに行った。
6000円コースを頼んだのだが結論から言うと超腹一杯うまい鮨を食える。 おまかせなのでメニューは選べないが私が行ったときはこんな感じ。恥を忍んでメモをとった。
個人的にはキンメダイの炙りがうまかった。
## 6000円コース 28品目 *付きはシャリ付き しじみ汁 *サクラマス にぎり 宮城めかぶ ほたて こぶじめ かつお たまり醤油のくぐり 湯葉くず粉 あわび *コハダ にぎり *キンメダイ あぶり にぎり みずだこ煮 *しろえび にぎり *くるまえびにぎり うめ茶碗蒸し *赤みにぎり *トロにぎり 子持ち昆布 ほたるイカあぶり *いくら + 茎山葵(お椀) たらこ西洋わさびつけ *青森ムラサキウニ *北海道バフンウニ ひょうたん柴漬け *ねぎとろ巻 しじみ味噌汁 *穴子にぎり 卵焼き *かんぴょう巻 すいか
写真は控えていたがウニだけは初めてちゃんと食べたので写真を撮った。

注:予約しないと基本入れなさそう。カウンターで大将の握るのを待つ時間が長いので友達と行くべし。
葬送のフリーレン
サンデーで連載されている漫画。よくあるRPG世界観風ファンタジーかなと侮っていたが思っていた以上に良かった。
読むとすごく優しい気持ちになれる。
 (少年サンデーコミックス)")
1話から魔王を倒した後のエピローグで始まる異色の構成だが,
今を生きる若者と旅しながらかつての旅の思い出を振り返る主人公の描写がアラサーには結構刺さる。これ少年向けか??
ジャンプの「チェンソーマン」「アンデッドアンラック」もそうだが,新しい世代の漫画はタメ回のようなものが少なく(特に序盤)ストーリー展開により無駄がない様に感じる。
感想として今の若手の子たち漫画うますぎない?となっている。
その他
書こうか迷っているが別に書くほどでもないなと思っているやつら。
- m1 macbook air
- 電池が持つだけでこんなにも使用感がいいのか!となる。現状開発はWSL2に寄ってるのでやや持て余し気味。
- vivy(2021年4月開始 SFアニメ)
- ターミネーター的な王道テーマをきれいな絵柄と丁寧な表情描写で描いているオリジナルアニメ。SFに飢えていたので今後に期待。
- 鎌倉 オクシロモン
- お洒落なカレー屋さん。うまい。以上。
- カレーつながりだと日吉のホアホアというアジアンダイニングのカレーが滅茶うまい。
- ふるさと納税全般
- 美味い。神。ありがとう我がふるさと。
- Oisix
- 献立を考えないというのがいかに楽かというのがわかる。でも高いのでやめた。
GitHub ActionsとMarkdownで書類作成 ~ Asciidoc編~
概要
下記記事のGitHub Actions版だと思えば良いです。
下記に出来上がった書類のサンプルを載せます。
https://yoshiri.github.io/MarkdownToAsciidocToHTML_CI/sample.html
Markdownからの変換手法
ここではMarkdownで書いた文をAsciidocに変換します。
MarkdownからAsciidocへの変換はPandocとKramdocの2択があります。
- Pandoc
- 言わずとしれた万能変換ツール
- 🙆数式などの変換がちゃんとしている
- 🙅タイトルへの変換
- Kramdoc
- Asciidoctorの開発側が開発した変換ツール
- 🙆章立てなどがきれいに変換される
- 🙅数式や一部書式が正しく変換されない
ここではPandocを採用します。(数式の書きにくいドキュメントはありえないので。)
ここで,Pandocで用いるコマンドを下記に示します。(DockerコマンドなのでPandoc環境がある人は適当に読み替えてください)
wsl docker run --rm -v $(pwd):/data pandoc/core: sample.md --to asciidoctor -o sample_pandoc.adoc --shift-heading-level-by=-1
引数の詳細などは下記を参照すると良いです。(本当は英語版サイトのほうがもっと良い。)
変換前提のMarkdownの書き方について
基本的な書き方はうまいこと変換されますが,気をつけなければ行けないのは章立てです。
通常の書き方をすると下記のようになると思います。
# 1章 ## 1-1節 ## 1-2 節 # 2章 ## 2-1節 ### 2-1-1節 ...
本記事で紹介する変換法を用いる場合文章は下記のように書くことを推奨します。 AsciidocのLevel1はHTMLのタイトル用であり,章がLevel2からスタートしていることに起因します。
# 文書タイトル ## 1章 ### 1-1節 ### 1-2 節 ## 2章 ... このように一つずつずらす。
または,マークダウンで見た時に不格好になるのが気にならなければ下記のようにかくのも良いでしょう。
= 文書タイトル ## 1章 ### 1-1節 ### 1-2 節 ## 2章 ... (上記は`--shift-heading-level-by=-1`のときの書き方)
理由は次で説明します。
pandocで下記のようなマークダウンを変換した場合,レベルを1段下げます。--shift-heading-level-by=-1を用いた時の挙動について
# 文書タイトル ## 1章 ### 1-1節
下記のようにAsciidocでは=が#のような役割を持ちます。
== 文書タイトル === 1章 ==== 1-1節
これに対して--shift-heading-level-by=-1を引数に加えることでレベル下げをキャンセルできます。 できるのですがタイトルのブッキングを避けるために下記のような結果を生成します。
文書タイトル <- 本当は"="から始まってほしい == 1章 === 1-1節
これを避けるもっとも手っ取り早い方法は最初からタイトルの装飾を"#"から"="に書き換えて置くことです。
置換でタイトルの"#"を"="に変更
タイトルの装飾を"#"から"="に書き換えて置くことで上記の問題は解決しますが,Markdownでこれを書くのは面倒。
ということで,GithubなどのCIの時点でタイトルの装飾を変えれば良いです。
具体的には,sedコマンドを用いて 文章の最初に出てきた"# "のを"= "に変えます。(タイトルはほぼ文章の最初に来るはずなので)
コマンドはこちら。
sed -ie '0,/# / s/# /= /' sample.md
workflowの定義
サンプルリポジトリをおいておきます。
workflowは下記のような内容です。
# This is a basic workflow to help you get started with Actions
name: CI
# Controls when the action will run.
on:
# Triggers the workflow on push or pull request events but only for the master branch
push:
branches: [ master ]
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# asciidoc to html
asciidoctor_job:
# The type of runner that the job will run on
runs-on: ubuntu-latest
name: Build AsciiDoctor
steps:
# Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it
- name: Check out code
uses: actions/checkout@v2
- name: Fix Title Level Issue
run: sed -ie '0,/# / s/# /= /' sample.md
- name: Markdown To Asciidoc
uses: docker://pandoc/core:2.11
with:
args: -f markdown+east_asian_line_breaks sample.md --to asciidoctor -o sample.adoc --wrap=preserve --verbose --shift-heading-level-by=-1
# Output command using asciidoctor-action
- name: Build AsciiDoc step
id: documents
uses: Analog-inc/asciidoctor-action@master
with:
shellcommand: "asciidoctor sample.adoc -r asciidoctor-diagram -a allow-uri-read -a data-uri -a toc=left"
# Use the output from the documents step
- name: move deploy files
run: |
mkdir build/
mv sample* build/
ls build
- name: deploy
uses: peaceiris/actions-gh-pages@v3
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
publish_dir: ./build
publish_branch: gh-pages
以上!
GitHub ActionsとMarkdownで静的サイト作成 ~ mkdocs-material 編~
目的
Markdownで書いた文書を静的サイトとしてまとめ上げたい。 そしてそのままそれを本番の文章として提出しちゃいたい。
なお,前回の記事はこちら。
要求:
- 検索機能つきの静的なサイトが生成される
- 表現が豊か(数式・図表・Admonitionなど)
- PDFに出力可能
超参考になるサイト:
ここから,mdbook, (gitbook), mkdocsあたりを試していこうと思います。
mkdocs-material
Pythonで動く静的サイト作成手法mkdocsのmaterialというテーマ。
Pros and Cons
- 🙆Pros
- 表現力が豊か(数式,PlantUML,Admonitionなど)
- 日本語検索にデフォルトで対応
- cssのカスタムテンプレートなどの数が多い
- 🙅Cons
機能性・拡張性では今の所mdbookよりも良さそうです。
Dockerを用いた動作
多くの人が入れているであろうPython環境で動くので自前でも動かせますが,Dockerイメージもあります。
自分はWSLでやっていますが,Docker for windowsの場合は適宜`pwd`を”%CD%”にするなど置き換えてください。
とりあえず動かす分にはsquidfunk/mkdocs-materialが多く使われている感じがします。
- 初期化
wsl docker run --rm -v `pwd`:/book/ squidfunk/mkdocs-material init
- build
wsl docker run --rm -v `pwd`:/book/ squidfunk/mkdocs-material build
ざっくり生成されるファイル・フォルダを説明すると
- book.toml : 書式や署名などを指定する
- src/ : 文書のソースを置く場所
- SUMMARY.md : リスト形式で文章のネスト構造を指定する
- xxx.md: 本体の文章
- book/ : 生成されたサイトがここに格納される。文章へはindex.htmlにアクセス。
Github Actionsを用いたドキュメントのHost
ひとまずテストプロジェクトを立ててみました。
なお,拡張機能をいろいろ盛り込んだので動作検証用のossyaritoori/mkdocs-materialにてイメージを公開しました。
したがって,実行コマンドは下記のような感じになります。
docker run --rm -v `pwd`:/docs ossyaritoori/mkdocs-material build
ファイル構造
ファイル構成はこんなかんじです。
mkdocsTest ├── .github │ └── workflow │ └── mkdocs.yml │ ├── mkdocs.yml # book setting └── docs # Source folder ├── index.md # For top page (Not neccesary) └── < other .md files >
.github以下のActionsについて
Actionの流れは
- ファイルをCIサーバーにUpload
- build
- docs以下をgh-pagesに展開
としました。
name: deploy mkdocs
on:
push:
branches:
- main
- master
jobs:
deploy:
runs-on: ubuntu-latest
steps:
# Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it
- name: Check out code
uses: actions/checkout@v2
# Prepare Python package
- uses: actions/setup-python@v2
with:
python-version: 3.x
- run: pip install mkdocs-material
- run: pip install plantuml-markdown python-markdown-math mdx_truly_sane_lists mkdocs-git-revision-date-localized-plugin mkdocs-add-number-plugin
# deploy
- run: mkdocs gh-deploy --force
gh-pagesの設定
上記のFlowではgh-pagesブランチに生成物をUploadしています。
gh-pagesの設定は「設定」→「一般」から下記の項目で
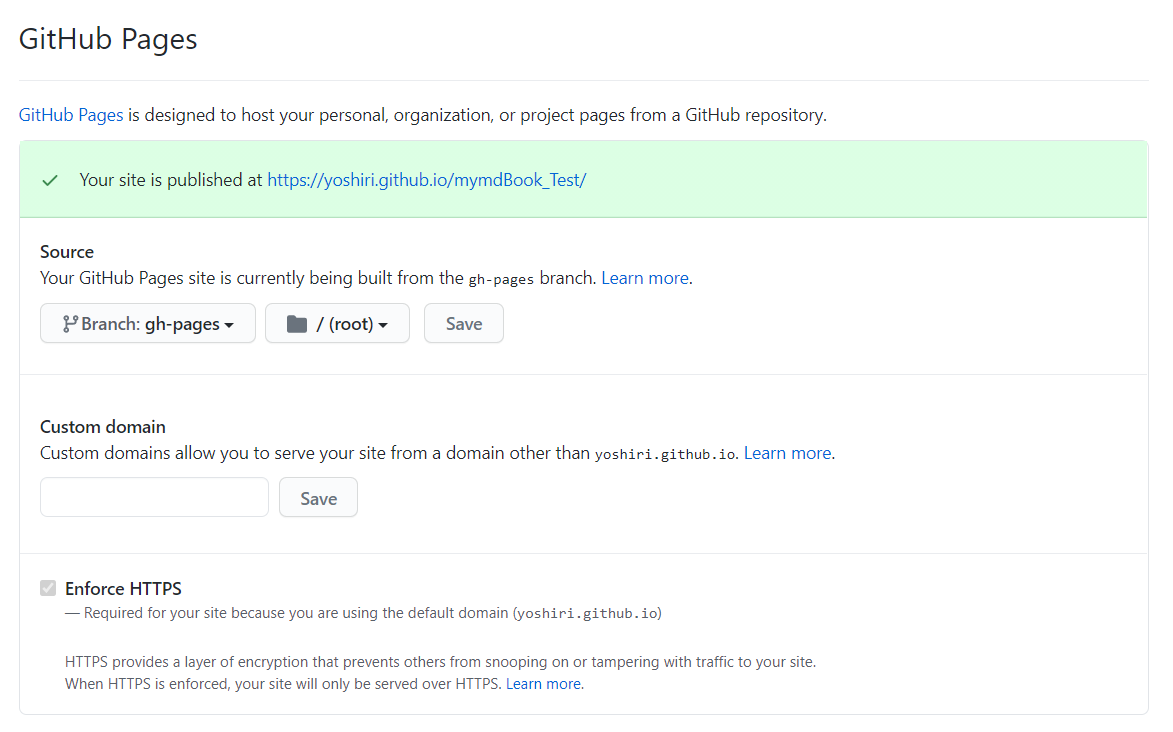
TODO・その他
GithubActionについて
面倒でそのままpipを手打ちしていますがRequirement.txtとかを書いてそこからインストールしたほうが良さそうです。 Dockerfileもそれに準拠して書かないとなぁとは思っています。
PDF生成
インストール後,CSSファイルをコンパイルして作成することでそれっぽくできます。
ただ,日本語が文字化けしてしまったのでそのあたりはCSSを調整してみないと,といった感じです。
GitHub ActionsとMarkdownで静的サイト作成 ~ mdbook 編~
目的
Markdownで書いた文書を静的サイトとしてまとめ上げたい。 そしてそのままそれを本番の文章として提出しちゃいたい。
要求:
- 検索機能つきの静的なサイトが生成される
- 表現が豊か(数式・図表・Admonitionなど)
- PDFに出力可能
超参考になるサイト:
ここから,mdbook, (gitbook), mkdocsあたりを試していこうと思います。
mdbook
開発が終了したGitbook v1のRust版後継です。
Pros and Cons
- 🙆Pros
- 動作が軽量。コンパイルが早い。
- サーバを建てずともサイトの検索機能が動作する
- 🙅Cons
- 現状日本語検索に対応する気があまりなさそう…
- 発展途上なので現状表現力は他の手法に劣る。
Dockerを用いた最小動作
Rust環境を建てても良いですが,Dockerで開発するのが無難です。
自分はWSLでやっていますが,Docker for windowsの場合は適宜`pwd`を”%CD%”にするなど置き換えてください。
- 初期化
wsl docker run --rm -v `pwd`:/book/ peaceiris/mdbook init
- build
wsl docker run --rm -v `pwd`:/book/ peaceiris/mdbook build
ざっくり生成されるファイル・フォルダを説明すると
- book.toml : 書式や署名などを指定する
- src/ : 文書のソースを置く場所
- SUMMARY.md : リスト形式で文章のネスト構造を指定する
- xxx.md: 本体の文章
- book/ : 生成されたサイトがここに格納される。文章へはindex.htmlにアクセス。
Github Actionsを用いたドキュメントのHost
ひとまずテストプロジェクトを立ててみました。
ファイル構造
ファイル構成はこんなかんじです。
mymdBook_Test ├── .github │ └── workflow │ └── mdBook.yml │ ├── book.toml └── src ├── chapters │ ├── introduction.md │ └── <other .md files> └── SUMMARY.md
.github以下のActionsについて
Actionの流れは
- ファイルをCIサーバーにUpload
- build
- book以下をgh-pagesに展開
としました。
name: github pages
on:
push:
branches:
- main
jobs:
deploy:
runs-on: ubuntu-18.04
steps:
- uses: actions/checkout@v2
- name: Setup mdBook
uses: peaceiris/actions-mdbook@v1
with:
mdbook-version: '0.4.6'
# mdbook-version: 'latest'
- run: mdbook build
- name: Deploy
uses: peaceiris/actions-gh-pages@v3
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
publish_dir: ./book
gh-pagesの設定
上記のFlowではgh-pagesブランチに生成物をUploadしています。
gh-pagesの設定は「設定」→「一般」から下記の項目で
TODO・その他
- ちょっときになる点
- 左のTitleが折り畳めない
- PDF生成とか試しておきたい。
Splatoon2で表示される文字をフォントから学習してTesseraactでOCRする
概要
- Splatoon2の録画の動画からカウントや時間,スペシャルなどの情報を抽出するためにOCRを行う
- コンテンツ
- TesseraactとjTessBoxEditorを用いてSplatoon2のフォントを学習
- pyocrを用いて画像から文字領域を抽出の上,OpenCVを用いて下処理・描画
背景
突然ですがIkaLogというツールを皆さんご存知でしょうか。 詳細は下記のスライドに任せますが,Splatoon1の時にプレイ画面を解析して試合の詳細な流れを記録するツールです。
www.slideshare.net
具体的には,ステージ名などの基本情報から敵味方の生存状況のタイムライン,スペシャルやカウントの進みなど多岐にわたる解析が可能だったようです。
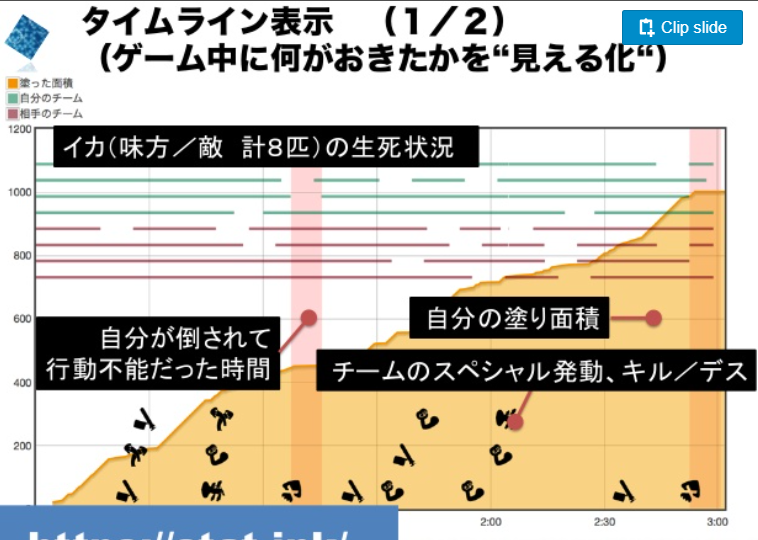
自分もスプラプレーヤーとして試合の流れなどの情報を一度整理したいと思い今回のツールを個人開発してみようと思い立つに至りました。
目指すところ
筆者の開発環境
参考までに筆者の開発環境を載せます。言語はPythonで重要なパッケージは以下のとおりです。
- Windows10 Home, Python3.6 in Anaconda
- OpenCV 3.4
- Tesseract 5.0 alpha
- pyocr 0.7.2
の上で動かすことを前提にしています(古くてごめん)。
OCR環境を整えてSplatoon2のフォントを学習する
本章ではまず,環境を整えてSplatoon2のフォントを学習するところからやっていきます。
ここでは下記の記事が大変参考になるので是非一読をおすすめします。というか細かい部分は下記を参照してください。
TesseractとPyOCR環境のインストール
Python上で学習を動かせるように環境を設定します。詳しくはこちらに任せるとして勘所だけ書いておきます。
インストール確認には下記のコマンドを実行してください。
import pyocr tools = pyocr.get_available_tools() for tool in tools: print(tool.get_name())
出力にTesseract (sh)が入っていれば成功です。
学習用ツールjTessBoxEditorのインストール
次に,フォントを新たにTesseractに学習させる時に使えるGUIツールをインストールします。
- JRE8.0以降の実行環境をインストール(インストール参考)
- ここでも環境変数を設定するので再起動しといたほうが無難
- jTessBoxEditorをDLしてくる
- DL後回答したフォルダで
java -Xms128m -Xmx1024m -jar jTessBoxEditor.jarを実行
- DL後回答したフォルダで
成功すれば下記のような画面が出てくるはずです。(画像出典: https://www.tdi.co.jp/miso/tesseract-ocr)
Splatoon2のフォントをDLしてくる
Tesseractに新たに文字を学習させるには文字のフォントが必要なのですがSplatoon2は任天堂オリジナルフォントで2次配布されていません。
フォントの製作は最も苦労するパートのハズですが,ここでは海外有志が作成したと思われるSplatフォントを用います。
インストールするにはDLしたttfファイルをC:\Windows\Fonts\にコピーします。
(上記フォルダにないとjTessBoxEditorが認識しなかったため。)

Splatoon2のフォントを学習する
- 学習用フォントファイルの作成
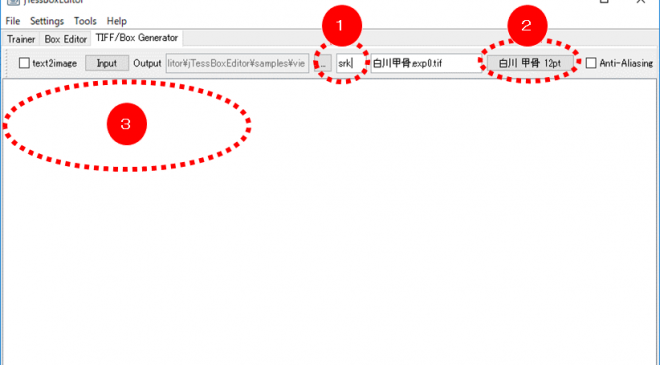
- iTessBoxEditorを起動し、「TIFF/Box Generator 」タブを開く。
- 上図(1)に学習済み言語を表す英字を入力。(これは後で言語として選択する時に使うもので自分で決めます。三文字を使うことが多いですが今回は「spl2」としておきます。)
- 上段の位置から「Splatフォント」を指定
- 学習したい文字を打ち込む。(打ち込んだ文字のみを学習する仕様のようです。下図では数値だけを学習する例を見せています。)
- Generateを押してboxファイルを作成する。

上記をすべて実行すると下記のようなファイル群が生成されるので後の工程のために任意のフォルダに移動すると良いです。
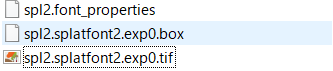
今回は数値のみを学習したsplというboxファイル,カタカナ文字を学習するspl2というboxファイルを作成しました。
カタカナの学習の五十音は下記のサイトからコピペしてきました。(本来は頻出の単語なども学習するっぽい(要検証)なので,スプラ2で使われる文字列などを学習したほうが良さそうです。)
学習の実行
こちらも上記文献の引用です。
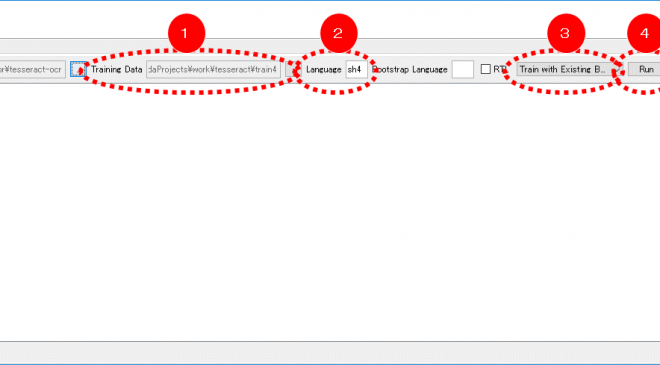
- iTessBoxEditorでの学習の実行。まず「 Trainer 」タブを開く
- Traininig Data(1):上記で生成したファイル「spl2.splatfont2.exp0.box」を選択。
- Language(2):「spl2」と入力。
- Training Mode(3):「Train with Existing Box」を選択。
- Run(4)を実行し,
** Moving generated traineddata file to tessdata folder ** (改行) ** Training Completed **のメッセージが出たら完了。
- 生成されたファイル
spl2.traineddataをTesseractの環境にコピー。- 自分の場合は,Programfiles以下の
C:\Program Files\Tesseract-OCR\tessdataに環境が合ったのでそこにコピー。
- 自分の場合は,Programfiles以下の
ここまでで完了。
結果だけ欲しい人用
上記の経緯は結局,「Tesseraactで使えるスプラトゥーンの文字フォント学習ファイルを生成」しているだけなので端的に結果のファイルをDLしてコピーできれば良いです。
とりあえず私が雑に作ったものを以下に載せます。
Splatoon2のカタカナを学習したフォントファイル。(Tesseract用)spl.train…
参考までに,似たようなことをやっている方として下記のような記事があります。
OpenCVとPILを用いてOCR結果を表示
Pythonのpyocrモジュールを用いてOCR結果を取得して図示するところまでやります。
image_to_stringという関数を用いるのですが大体下記2つについて書きます。
PyOCRのimage_to_stringでOCRする
とりあえず初めて使うパッケージは公式ドキュメントを見よというのが鉄則なんですが全然検索の上位に出てこないので結構キレそうになります。
一応まともそうなのは下記でしょうか。
また,下記の記事なども参考にしました。
私が使った関数は
tool.image_to_string( <PIL image>, lang="spl2",builder=pyocr.WordBoxBuilder())
というものです。
引数についての説明は以下の通り。
- tool:pyocr.get_available_tools()にリストで入っている一要素。今回は
tool = pyocr.get_available_tools()[0]でOK。 - Image :cv2(numpy)の画像ではなくてPILのImage形式で入れる
- lang:使用する検出言語。日本語なら”jpn”,英語なら”eng”,今回はカタカナを認識するので先程学習した”spl2”を用いる
- builder:どのような出力を吐き出すかを変更できる。今回は位置と単語と確信度を抽出できる
pyocr.WordBoxBuilder()を使用。
特にPILのImage形式で入れなければ行けないのがだるいためcv2とPILとの変換関数を用意する必要があります。
ということで変換を含めた関数ファイルは下記の通り。
import pyocr import cv2 import numpy as np import pyocr.builders import matplotlib.pyplot as plt from PIL import Image, ImageDraw, ImageFont def cv2pil(image): ''' OpenCV型 -> PIL型 ''' new_image = image.copy() if new_image.ndim == 2: # モノクロ pass elif new_image.shape[2] == 3: # カラー new_image = cv2.cvtColor(new_image, cv2.COLOR_BGR2RGB) elif new_image.shape[2] == 4: # 透過 new_image = cv2.cvtColor(new_image, cv2.COLOR_BGRA2RGBA) new_image = Image.fromarray(new_image) return new_image def extract_imageboxes(img,lang_setting="jpn",tool = tool, builder = pyocr.builders.WordBoxBuilder(),): """ img: opencv img lang: language setting builder """ LineBoxes = tool.image_to_string(cv2pil(img),lang_setting, builder = builder) res = {} for lb in LineBoxes: dic = {} dic["position"] = lb.position dic["confidence"] = lb.confidence res[lb.content] = dic return res
返り値として,検出した文字列をKeyにした辞書型オブジェクトの辞書を返します。 使用例は後ほど。
PyOCRの検出結果を描画する
PyOCRで検出した結果,「テキスト」,「BoundingBox」,「確信度」が帰ってくるのでこれを可視化します。
具体的には下記の画像のようにします。
- 日本語テキストを書き込む
- BoundingBoxを書き込む
- 確信度によって色を変える

OpenCV画像に日本語テキストを書き込む
簡単のように見えて一番だるい作業でした。下記の記事を改変して作業しています。
下記改良版においては一度画像をPILに変換してからPILの関数を用いて書き込んでいます。
これらの機能のまとめ
以上の
- extract_imageboxes:OCR情報抽出
- cv2_putJPText:日本語書き込み関数
の2つと色変換の関数を加えて画像を直接加工するshowWordBoxesAndText関数を作りました。
def hsv_to_rgb(h, s, v): bgr = cv2.cvtColor(np.array([[[h, s, v]]], dtype=np.uint8), cv2.COLOR_HSV2BGR)[0][0] return (int(bgr[2]), int(bgr[1]), int(bgr[0])) def showWordBoxesAndText(img,showimg=None,lang_setting = "jpn"): """ opencv画像を元にpyocrで読んだテキストをBoundingBoxと一緒に書き込む。赤味が強いほど確信度が高い。 """ imgshow = img.copy() if showimg is None else showimg.copy() dics = extract_imageboxes(img,lang_setting) print(dics) # 一応結果が見たいのでShowしている #fontpath ='C:\Windows\Fonts\MEIRYOB.TTC' # メイリオを指定する場合。Windows10 だと C:\Windows\Fonts\ 以下にフォントがあります。 for dic in list(dics.keys()): if len(imgshow.shape) == 2: fontcolor = int(2.55 * dics[dic]["confidence"]) else:# color image fontcolor = hsv_to_rgb(2 * dics[dic]["confidence"],255,255) text = dic cv2.rectangle(imgshow, dics[dic]["position"][0], dics[dic]["position"][1], fontcolor) cv2_putJPText(imgshow,text ,dics[dic]["position"][0],fontScale=15,color= fontcolor,mode=1) return imgshow
その他コツ
いくつかのサンプルを試した結果下記のようなことが言えそうです。
- 大きな画像ほど文章抽出が困難になるのでなるべく読みたい文字に対して領域を小さく区切って検出する
- 文字が白いなどの付加情報があるなら事前に色や輝度でマスクすると捗る
- 確信度(Confidence)でフィルタリングするのは雑音除去に有用だが稀に
半角スペースが高い信頼度で検出されるので弾く必要がある- 具体例:
{' ': {'position': ((0, 0), (0, 151)), 'confidence': 95}}みたいなかんじ。
- 具体例:
他にも傾向などありましたら聞きたいです。
適用結果とその比較
ということで,上記の関数を使って抽出してみました。 比較として,デフォルトでDLできる日本語検出”jpn”と今回学習したスプラトゥーン2のカタカナフォント”spl2”を指定した際の違いをお見せします。
スペシャル情報
まず,スペシャルの文字列を検出したときですが,
| デフォルトの”jpn”で検出した結果 | 学習した”spl2”で検出した結果 |
|---|---|
 |
|
このように完璧ではないですが欲しい情報に近いものが得られました。(実際スペシャルを知りたいだけなのでこれくらいならその他文字列との距離を取れば余裕で分類できそうです。)
試合時間・カウント
試合時間は中央の固定領域にあるので領域指定して抜き出せば簡単に呼べます。 この数値に限って言えば,別に英語のOCRでも正しく検出出来ました。
| デフォルトの”jpn”で検出した結果 | 学習した”spl”で検出した結果("eng"でも同様の結果) |
|---|---|
 |
 |
一方でカウントは簡単かと思いきや,下記のように広い領域では何も検出できませんでした。

白い領域を抽出後,下記程度に範囲を絞って下の画像のレベルまで情報を整理してようやく正しく検出が出来たのでそのあたりはちょっと調整が必要そうです。

ルール名・タイトル
ルール名も精度が悪いです。これは比較的簡単な理由で,ルールのフォントは学習したフォントとは若干違うからです。 この辺を改善しようとすると学習器のチューニングが必要ですが,4つのルールを分類出来さえすればいいのでうまいこと距離を導入できればなんとかできそうです。
| デフォルトの”jpn”で検出した結果 | 学習した”spl”で検出した結果("eng"でも同様の結果) |
|---|---|
 |
 |
おわりに
ということで,PyOCRとTesseractを用いてスプラトゥーン2の画面情報を読み取ろうという記事でした。
本当はアドベントカレンダーに載せようと思っていたのですがあまりにも諸エラーや記事の執筆に時間がかかってしまったため遅刻&中途半端な記事になりました。すいません。
他にもスプラ愛好家として以前,Splathon2で散々言われている編成などの「勝ちにつながる要素」を定量的に解析しようというのをやっていたりして,今中途半端になっているのでそちらもうまいこと計画して進めて行きたい所存です。
TODO
やりたいことはあるのですが1月は結構仕事が忙しそうなのでしばらくまた休眠するかもしれません…
- 一連のコードを整理して公開
- 記事のブラッシュアップ
- 検出した結果を元に動画から一通り情報を抜いてみる
- 適切な距離を定義して検出単語を分類
- 前処理とかも含めたコードの整理
- 頻出な単語を学習することで検出精度の向上?
- プロジェクトを進める
超余談:Gistにバイナリを上げる方法
バイナリはドラッグアンドドロップ出来ないので無理だと思っていたがどうやら下記の方法で普通にアップできます。結構面倒ですがまぁヨシとします。
- 適当なGistを建てる
- URLをコピってClone
- バイナリを追加・リポジトリ修正してPush
Latexを使ってふるさと納税で必要な身分証明証のコピー画像をまとめて印刷する
ふるさと納税のワンストップ申請は翌年1/10まで!!
概要
- ふるさと納税のワンストップ申請ではたくさんの身分証明証(例:マイナンバーカード)を印刷して貼る必要がある
- 毎回印刷していると紙と印刷代がもったいないので実寸代に敷き詰めて印刷できるようにPDFを生成する
- 昔名刺を印刷する時に書いたLatexを流用してパッケージ化
モチベーション
ふるさと納税をしようとしたところ,ワンストップ申請ごとに身分証明証のコピーを貼る必要があったためこれらを大量に印刷する必要性に駆られました。
問題として,
- プリンタもスキャナもないのでコンビニにいかねばならない。複数印刷するのは手間だし高い。
- Wordみたいな文書にスマホで撮った画像を複数貼って実寸のサイズに合わせて,一枚一枚貼って…というのが面倒
というのがあったため,下記のようにまとめて印刷できるような版組をLatexで組んでみました。

関連記事
- 今回のパッケージのリポジトリはこちら
- 名刺を作ったときの過去の記事
パッケージの使い方
必要な環境
- Latex(pLatex)をでコンパイルできる環境。geometry.styが入っていることが必須。
- 名刺か身分証明証の表面と裏面の画像(スケールは問わないがアスペクト比は正しくすること)
- スマホで真上から撮ってペイントで切り抜くとかでもOK
- コンパイル用のLatexファイル。
IdentificationCard.tex