DeepLで翻訳したPDFから文章を抽出する(Python,Apache Tika)
はじめに
DeepLの無料版会員は月に3度までPDFやWORD文章などを翻訳にかけることが出来ます。
本記事の概要を下記3行にまとめます。
- DeepLで翻訳したPDFは保護がかかっており,印刷したり文章をカーソル上でコピーすることができない
- Python環境があればこれを抽出することができる
- DeepLの使用規約には抵触していないはずだが指摘されたら消します
参考サイト
Apatch Tikaというドキュメント分析・抽出ツールを使いますが関連する手法などについて下記を参考にしました。
今回はやりませんでしたが直接DeepLのAPIを叩くのも良いと思います。
抽出手順
環境設定
Windows10のAnaconda3のPython3.6の環境で実行しています。(古くてすみません)
抽出に用いるパッケージは下記コマンドでインストールできました。pipと混ぜるのが嫌な人は別で環境を立てたほうが良いと思います。
pip install tika
抽出と後処理
元のURLを参考にtxtへの書き出しをするプログラムを先に記します。
from tika import parser file_data = parser.from_file("extract-sample.pdf") # この部分でPDFを読み込み text_ = file_data["content"] # テキストを抽出 print(text_) # 確認 text = text_.replace("\n\n","") # 二重改行が多かったので置換して除去 with open("out.txt", "w", encoding="utf-8") as f: f.write(text) # 日本語を扱うのでUnicodeを指定して書き込み
parserが呼ばれている行で変換が行われ,初回実行時にはインストール画面のようなものが出現します。その際には下記のようなログが出ますが気にしなくて良さそうです。
2022-04-24 16:34:20,224 [MainThread ] [INFO ] Retrieving http://search.maven.org/remotecontent?filepath=org/apache/tika/tika-server/1.24/tika-server-1.24.jar to C:\Users\xxxx\AppData\Local\Temp\tika-server.jar. 2022-04-24 16:35:14,657 [MainThread ] [INFO ] Retrieving http://search.maven.org/remotecontent?filepath=org/apache/tika/tika-server/1.24/tika-server-1.24.jar.md5 to C:\Users\xxxx\AppData\Local\Temp\tika-server.jar.md5. 2022-04-24 16:35:15,777 [MainThread ] [WARNI] Failed to see startup log message; retrying...
また,出てきた文書は見た目をベースに改行などのスペーシングも文字として認識されており,私の文書のケースだと二重改行が目立ったので事前にReplaceしておきました。これもPythonを使う利点ですね。
余談:ですます変換
DeepLの翻訳結果は基本的にですます調になり,たまにである調が混ざるという調整が必要なものになります。
WORDにはですます調を検知することはできますが,これを一括で変換してくれないので下記のサイトを使うのが今のところ一番楽そうです。
時間波形のsin波のゲイン・位相の変位を計算する(Python/Numpy)
概要
システム同定などのシチュエーションで単一のsin波を入力し、出力される波形とのゲインと位相差を計算したい場面があったので作成しました。
波形がSin波に似通っている&周波数がわかっているならば直交性を用いた解法が良さそうです。
下準備:時系列データ作成
時刻の作成ではnumpyのarangeとlinspaceと仲良くなると良いです。
import numpy as np import matplotlib.pyplot as plt N = 1000 # 1000 sample data sample = 0.001 # 1ms freq = 5 # 5Hz # 時刻作成 t = np.arange(0,sample*N,sample) # 位相ズレ付きのSin波を作成する無名関数 x = lambda phi: np.sin(2*np.pi*freq*t+phi ) # 信号作成 y1 = x(0) y2 = x(1.3) # 1.3 rad/s ずれたsin波
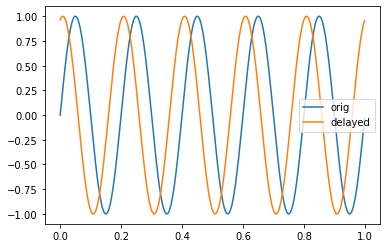
直交性を用いた解法
ゲインと位相を知りたい信号がとすると、
と
の直交性から下記のような式が導けます。
この を十分長い時間で平均すると、
の項のみが残ります。
同様にともとの信号の各時間での値をかけ合わせた数値
を十分長い時間で平均すると
が残るのでこれらを用いてゲインと位相が計算できる、という手法です。
def get_mag_and_phase(y,x):
"""
y: input signal
x: lamda function
"""
cos_ = x(0)
sin_ = x(np.pi/2.0)
N=len(y)
a = sin_ * y
b = cos_ * y
A,B = a.sum()*2/N ,b.sum()*2/N
mag = np.sqrt(A**2+B**2)
phase = np.arctan2(A,B)
return mag, phase
def calc_mag_and_phase(y1,y2,freq,st):
"""
input:
- y*: signal
- freq_dot_t: frequency[Hz] * samplingtime [s]
"""
N = len(y1)
w = 2* np.pi* freq
time = np.arange(0,N*st,st)
x = lambda phi: np.cos(w*time+phi)
mag1, phase1 = get_mag_and_phase(y1,x)
mag2, phase2 = get_mag_and_phase(y2,x)
return mag2/mag1, phase2-phase1
print(calc_mag_and_phase(y1,y2,freq,sample))
プログラム内では入力と出力の2つの信号の他に一度sinとcosの波を作ってそことの差分からゲインと位相差を計算しています。
これの明確な欠点として、下記の2つが挙げられます。
- 入出力の信号に無限時間平均で0にならないノイズがのっていると誤差が発生する
- 入出力信号の長さが周期の整数倍でないと誤差が発生する
前者はRANSACのような繰り返し処理による外れ値除去、後者は周期の整数倍になるように信号の時刻をCropする手が挙げられます。
後者に簡単に対応すると下記のような感じでしょうか。
def calc_mag_and_phase2(y1,y2,freq,st):
"""
input:
- y*: signal
- freq_dot_t: frequency[Hz] * samplingtime [s]
"""
N = len(y1)
w = 2* np.pi* freq
t_max = np.floor(N*st)
N_ = int(t_max/st)
time = np.arange(0,t_max,st)
x = lambda phi: np.cos(w*time+phi)
mag1, phase1 = get_mag_and_phase(y1[0:N_],x)
mag2, phase2 = get_mag_and_phase(y2[0:N_],x)
return mag2/mag1, phase2-phase1
別解
下記サイトに様々な手法が載っています。上記の手法とどう違うのか式を追えてないのですが、
余談:Cross-Correlationで位相計算にずれが生じる
確か波形のズレを調べるだけならCross-Correlationから波形のズレが測れるはずだよな、と思い下記のコードを試してみました。
from scipy import signal corr = signal.correlate(y1,y2,method='auto') lags= signal.correlation_lags(len(y1), len(y2)) plt.plot(lags,corr) amax = corr.argmax() amin = corr.argmin() print((lags[amax])*sample*2*np.pi*freq)
結果は 1.2566370614359172 となんとも惜しい値。相互相関の計算では時間軸上で-∞から+∞までの積分を想定しているため繰り返し数が足りないのでは、というお話でした。
他にも位相相関も試してみましたが似たような問題で正しい値が出なかったので注意です。
def phase_corr(sig1,sig2):
N = len(sig1)
fft_sig1 = np.fft.fft(sig1)
fft_sig2 = np.fft.fft(sig2)
fft_sig2_conj = np.conj(fft_sig2)
R = fft_sig1*fft_sig2_conj
R/=np.absolute(R)
r = np.fft.fftshift(np.fft.ifft(R).real)
ar = np.unravel_index(r.argmax(), r.shape)
plt.plot(r)
return ar[0]-N/2, r[ar]
PytorchのPretrained Modelを使ってSegmentationを行う個人メモ
はじめに
本記事はあくまでML初心者の筆者の個人メモです。
pytorchの出来合いのモデルを使って画像認識タスクのうちSegmentationを行うことを目標にします。
実行環境
環境が汚れにくく、実行も高速なGoogleColabを使用します。
必要なデータはwgetなどでDLしてきても良いですし、下記のコマンドで簡単にGoogleDriveとも接続できるので簡単で便利です。
# mount drive from google.colab import drive drive.mount('/content/drive')
torchvisionのモデルを使ったsegmentation例
pytorchで使用できる既製のモデルはいくつかありますが、ひとまずtorchvisionで使えるモデルを使ってsegmentationを行っていきます。
先に作例を示すと 某所から借りてきた星野源氏の下記写真から人物の部分のみを抜き出すことができたりします。


1. モデルを選んでロード
はじめに、欲しい機能を実現するモデル(と学習済み重み)を選びます。
モデルはCNNのネットワーク構造、学習済みの重みはどのデータセットで学習したかを表します。
- torchvisionで使用できるモデル
- FCN ResNet50, ResNet101 FCNについて参考
- DeepLabV3 ResNet50, ResNet101, MobileNetV3-Large DeepLabについて参考
- LR-ASPP MobileNetV3-Large
- モデルの学習済みパラメータ
- Pascal VOC on COCO
学習済み重みをどのデータセットで学習したかにはきちんと気を配る必要があり、例えばtorchvisionのモデルは人等を含む20クラス分類でしか学習していないのでそこにない物体を検知・抽出するには新たに転移学習をする必要があります。
下記では試しにFCNのresnet50を選んで試してみます。
import torchvision # 試しにresnet50を用いる model = torchvision.models.segmentation.fcn_resnet50(pretrained=True) # pretrained = Trueとすることで学習済みのモデルがセットされた状態になる。 model.eval() # モデルを評価用に切り替える。逆に学習するときはmodel.train()とする。おまじないと思って良い。
2. モデルのパラメータを確認
モデルを選んだら次は下記のパラメータを事前に確認しておきます。これは後述の画像を入力するときに必要になります。
- モデルの入力となる画像のサイズ
- 学習時の正規化項(mean, std)

今回のFCNのresnet50の場合、
- 入力の画像サイズ:224x224
- 正規化項:mean = [0.485, 0.456, 0.406] and std = [0.229, 0.224, 0.225] (範囲が0〜1であることに注意)
となります。
3. 画像の読み込みとモデルへの入力
以上の情報をもとに画像をモデルへとmodel(img)と入力すれば結果を得られるのですが、ここで前処理と型変換が問題になってきます。
よくあるNumpyの画像が[縦、横、RGBチャンネル数]のnp.arrayとなっているのに対し、今回使うsegmentationのモデルでは[バッチ数, カラーのチャンネル数, 横, 縦]という並びのTensorになっていなければいけません。
実際のコードでは同じ画像を下記の形式で行ったり来たり初学者にはとてもconfusingです
PILとtorchvision.transformsを用いた前処理
一番簡単かつ便利な手法で、torchvisionのtransformsを用いることで簡単に前処理を実装することができます。
具体的には下記のようなコードで前処理を書くことができます。
from torchvision import transforms from PIL import Image # 前処理用 preprocess = torchvision.transforms.Compose([ transforms.Resize((224,224)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) # load image img = Image.open("img.png") # Get Normalized image img_tensor = preprocess(img) # バッチサイズにあたる次元を一つ追加 img_input = img_tensor.unsqueeze(0) # 推論 output = model(img_input)
途中のpreprocessでは画像のリサイズやTensor形式の変換、画像の正規化を定義しています。
そしてこのオブジェクトに直接PIL形式の画像を与えることで任意の変換を行うことができます。
先程述べた、下記のパラメータをきちんと反映させていることを確認してください。
- 入力の画像サイズ:224x224
- 正規化項:mean = [0.485, 0.456, 0.406] and std = [0.229, 0.224, 0.225] (範囲が0〜1であることに注意)
他のtransformsに関しては公式か下記が参考になると思います。
numpyを用いた際の前処理
一応numpyを使っても前処理はできるのですがtorchvision.transformsが便利すぎて素直に変換したほうが良いです。
# PIL Image -> numpy array np_img = np.array(pil_img) # numpy array -> PIL Image pil_img = Image.fromarray(np_img))
なお、この場合でもuint8かfloat32かどうかや、RGBかBGRかは気を使う必要があります。
4. 結果の解釈
サクッと飛ばしましたがモデルへの入力はmodel(x)のように計算できます。
model.forward()やそのままmodel.predict() でもできることがあるようですが違いは追々調べます…
出力結果がどの結果に属するかのマスクになるのですがこちらもTensor形式なのでnumpy arrayかPIL Image 形式にして図示する必要があります。
今回はなるべくPILへと変換します。何度も言いますがtransformsが楽なので。
可視化の際には公式のチュートリアルと同様にsoftmaxで正規化すると良いです。
- マスクの作成
from torch.nn.functional import softmax # torch.Size([1, 21, 224, 224]) -> torch.Size([21,224,224]) output_ = output['out'].squeeze() # normalize normalized_masks = softmax(output_, dim=0)
- 可視化
def visualize_tensor(tensors): n = len(tensors) plt.figure(figsize=(24, 5)) for i in range(n): img = transforms.ToPILImage()(tensors[i]) plt.subplot(1, n, i + 1) plt.xticks([]) plt.yticks([]) plt.imshow(img) plt.show() visualize_tensor(normalized_masks)
可視化した結果が下記のとおりです。VOCでは1番目が背景、16番目がPersonとなっていますがそれに該当する箇所がハイライトされていることがわかります。

draw_segmentation_masksを使った可視化
draw_segmentation_masksというTensorを引数にとる関数があるっぽいので試してみました。
一見便利そうですがTensorを引数にするのがちょっと癖があって難しいなと思いました。numpyならマスキングは非常に簡単だと思います。
import torch wid,hei = img.size reshape_tensor = transforms.Compose([ transforms.ToPILImage(), transforms.Resize((hei,wid)), transforms.ToTensor(), ]) img_to_tensor = transforms.Compose([ transforms.ToTensor(), transforms.ConvertImageDtype(torch.uint8) ]) person_mask = reshape_tensor(normalized_masks[15]) > 0.5 bg_mask = reshape_tensor(normalized_masks[0]) > 0.5 person_img = torchvision.utils.draw_segmentation_masks(img_to_tensor(img), person_mask) bg_img = torchvision.utils.draw_segmentation_masks(img_to_tensor(img), bg_mask) visualize_tensor([bg_img, person_img])

numpyを使うパターン
numpyの方は変換さえできればstraightforwardなのでさっくり書くにとどめます。
# tensor to numpy out_np = reshape_tensor(normalized_masks[15]).detach().numpy().copy() mask = (out_np > 0.5) mask = cv2.cvtColor(mask.astype(np.uint8), cv2.COLOR_GRAY2RGB) masked = img_np * mask
参考・その他
とりあえず書き溜めておきます。汚ければ後で消すかもしれません。
参考になりそうな記事たち
大量の記事を斜め読みしたのでどれがどの参考になったかちょっと忘れてしまったのですがこれは確実に読んだというのを下記に記しておきます。
超初心者の抱えていた疑問と回答
とりあえず動かしていくにあたって感じたが疑問と現時点での自分の理解を書いておきます。
夫婦共働きにおける家計管理どうしてますか? 〜 我が家のケース 〜
はじめに
現在の日本にて夫婦共働きという家庭は結構あるかと思います。
しかし、肝心な家計管理の手法については下記のようなまとめサイトばかりで実際どのようにやりくりしているのかといった情報が少ないように思います。
この記事はひとまず自身のケースを備忘録として公開して、あわよくば他の方の情報も聞きたいという趣旨のもと書かれています。
目指す運用
前提
大前提として、
- 夫婦共働き
- 年収や労働時間に極端な差がない
こととします。また、ちゃんと話していませんが家計管理の目的は「支出の管理と貯蓄」にあるものとします。
家計管理に求めるもの
とりあえず家計管理のシステムに求めるのは下記の2点です。
- 貯蓄や日常生活の支出については明確に管理したい
- 私費や趣味に使ったお金はある程度相手からわからないようにしたい
また、原則として以下のような思想のもとやりくりを考えています。
- 必須なもの・面倒なものは自動化
- それ以外は人の手で調整できる余地を残す
家計管理サンプル
とりあえず、我が家でやっていることを下記に記します。
共有口座

個人で持つ口座の他に共有口座を一つ作って、そこから家賃などの固定費を支払うようにしています。
入金額はお互い相談して決めますが、固定費より多めに入れることで貯蓄用の口座としても振る舞えるようにしています。
良い点
- 年ごとに決まった固定額を入れるだけなので管理が楽。
- 個人の細かな出費を共有しなくても良いので気楽。
課題に感じる点
- 結局、共有口座よりも個別口座にお金が溜まっている(いくら入れるか問題)。
- 相手の個別口座や資産の状況についてあまり把握できない。
- 年1で年間の収支を共有するイベントをするのが良いと思うがまだやってないのでわからない。
貯蓄用と固定費用の口座は分けるという意見もあるようですが、口座を増やすと管理がめんどくさそうなので今のところはやっていないです。
家のための支払いの集計
食べ物の買い出しなどを始めとする「家のための買い物」はお互いが気づいたときにそれぞれ行うためどうしても出費に差が出てしまいます。
会社での経費申請のように購入時のレシートをもとに集計して支払いの差額を可視化するようにしています。
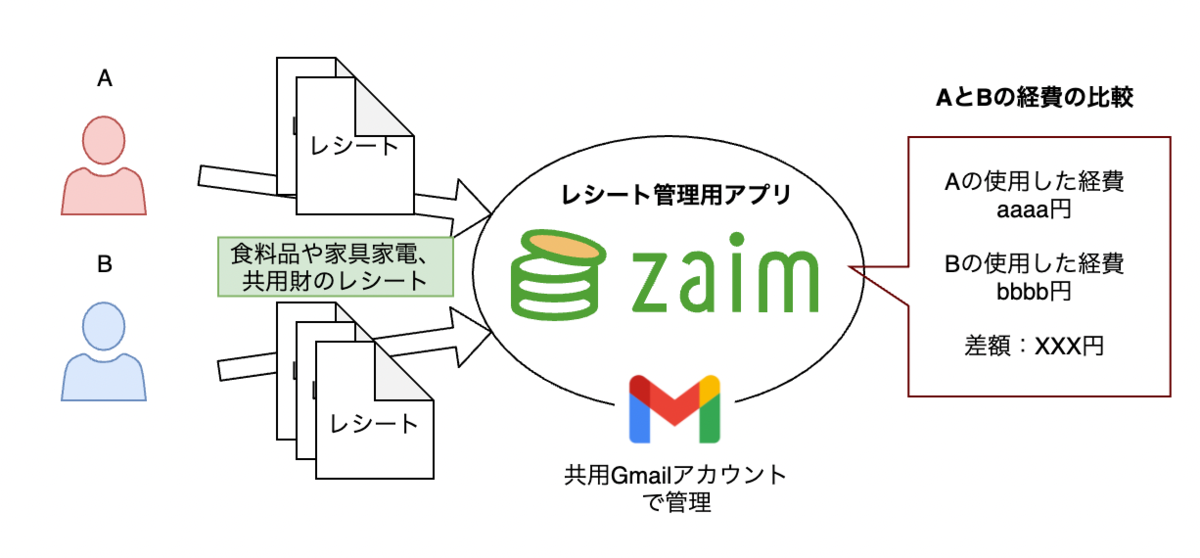
※ Zaimの採用理由(クリックして展開)
ちゃんと検討したわけではありませんが、下記のような理由でZaimを採用しました。
Tips
良い点
- レシートを撮影するだけで全て登録できるので慣れれば早い
課題
- 個人の収支管理(Money forward)と二度手間な感じがする
- 物品を確認することをしないので悪意があれば容易に経費申請しまくれる(脆弱)
わからないこと
個別口座と共有口座の貯蓄の比率
大体の場合、個別口座と共有口座のそれぞれで貯蓄をしていくこととなるかと思いますがこれをどちらに振るべきかわかっていません。
共有口座はどちらかの名義で作られることが多いかと思いますが、場合によっては口座名義人へのパートナーからの「贈与」として税務署に目をつけられるケースもあるようです。(もっとずっと先の話な気もする。)
個別口座に貯めるとするとお互いにどれくらい貯めるかなどの合意をきちんと取る必要があるのが大変そうに感じます。
個別口座情報の共有(全体の支出をどう集計するか?)
今まで話したとおり、お互いに個別管理の口座には突っ込まないのが前提になっていますが、とはいえ家計全体の収支やその内訳は把握しておきたいわけで年1などで決算報告などをする必要があるイメージでいますがこのあたりを具体的にどうやるかまだ決めていません。
最低限、
- 収入と支出額、投資口座の金額
- 支出の内訳(カテゴリ毎)
は知りたいはずですがうまいこと細かい情報にマスクしつつ知りたい情報を共有する仕組みがあればいいなと思います。
調べると、今はOsidoriというアプリが無料でそのあたりの機能をそろえているそうなので気になっているところです。
おわりに
ということで家計管理@我が家のケースをご紹介しました。
共有口座とレシートで家計での経費管理をすることでそれなりに公平そうな仕組みにはできていそうですがもっと良い方法があるなら知りたいです。
一つ確実にオススメできるのは夫婦で何かと外部とやり取りする際、共有のGoogleアカウントがかなり便利(メール・TODOの共同編集やアプリ連携など)ということです。
オドメトリを連結している別の座標系に移す時の座標変換計算(ROS)
概要
下記のようなシチュエーションのオドメトリ変換を考えます。
Bodyに固定したセンサでとったodometryをbase_linkでのオドメトリに変換するのが目的です。 (ROSでよくあるシチュエーションだと思います。)
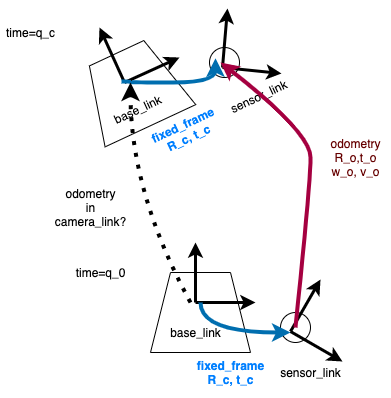
注意:速度変換の部分に自信がないです。詳しい方訂正・コメントお願いします。
tfを使った解法
ROSを使う人なら位置変換に関しては普通にROSのtfを
/base_link(q_0) -> /sensor_frame(q_0) -> /sensor_frame(q_c) -> /base_link(q_c)
のような感じでつないでlookupTransformで解決すれば位置の変換が取得できるとお思いになるかと思います。 一方で、速度(twist)の解決は私の知る限りサポートされていないように思います。
一応、lookupTwistというのがあるのですがこれはlookupTransformの結果を数値微分しているっぽいのであまり正確な値は期待できません。
また、複数のセンサがある場合などは複数の経路ができてtf treeの構造を壊しかねないのでエスケープのために余計なリンクをたくさん定義することになります。
自分で計算するときの数式
以上の課題を解決するために自分で計算していきます。
位置の変換
同次行列をつないでいけば、base_linkの座標系で見たOdometryのPoseは
で計算できます。これを全て計算すると下記のようになります。
ここで、が可換の時、具体的にはyaw回転しかしない自動車などのアプリケーションでカメラを水平に構えた時などは
とすることができます。
どこかが違うtwistの変換 (Pose変換の微分で解く)
Poseの変換がわかったので上記の式を時刻qで微分することで、Twist変換に変換することができます。(よね?)
なんか上記の仮定が間違っている気がしてきました。 一応途中式は残しておきます。結果が少し異なるのですが何が違うのかちょっと自信がないので
何かがおかしい気がする導出
記述量削減のため と記述することにします。
ここで
は角速度で、
はその交代行列です。この辺の話は面白いのでぜひ参考文献をご覧あれ。
のみが時変なので微分は下記のように計算できます。
角度の関係は
を解いて
となります。角速度の関係は参考文献[2]からと簡単な形に求まります。
並進速度は下記の感じになります。
また、R_o R_c が可換のケースでは下記のようになります。
並進速度の第一項は回転に伴うモーメントのような項ですね。
twistの変換 (多分こっちが正しい。)
twist(速度・加速度)の変換に自信がなく結構調べたのですが 調べる際によく出る例として下記の質疑があります。参考文献[4]のスライドがいい感じだと思われます。
要約すると座標Aで見た速度を座標A'で見たときにどうなるかを表す式は
とかけるというものです。
自分の変数に書き下すと下記の通りになります。vは並進tを時間微分したものです。
ここで、は角速度ベクトルの交代行列であり、
のように微小回転行列を表せます。
この辺は結構面白いのでリー代数や三次元回転についての記述を参照してください。(参考文献1)
展開すると並進速度は外積の性質などを用いて、
とかけます。
- 導出
導出の元になる数式は下記のようになっています。
角度について展開すると
となります。角速度の関係は参考文献[2]からと簡単な形に求まります。
並進速度は下記のように書けます。
補足
- 交代行列について
の時、
この行列は下記の性質を持ちます。
の導出
スマートな解釈としては参考文献[3]の式(8)あたりを見てもらうと良いですが、実は以下の2式をゴリゴリ成分計算することでも求まります。

まとめ
ということで機体から の位置に取り付けられたセンサのオドメトリ
から得られる機体のオドメトリ
は
で表されます。上から順に計算するなら右側の別解を使ったほうがスムースかと思われます。
なお、回転がYawしかないような特殊ケースでR_o,R_cが可換の場合は
となります。
正直Twistの速度の変換は下記の数式と異なるためどこか間違えている気がしないでもないのでご指摘よろしくおねがいします。
参考文献
フォーマット適当ですが下記の文書が参考になります。
[1] 金谷先生 「3次元回転: パラメータ計算とリー代数による最適化」

[2] 角速度ベクトルと回転行列の時間微分【力学の道具箱】 | スカイ技術研究所ブログ
[3] ベクトルの成分表示と座標変換【力学の道具箱】 | スカイ技術研究所ブログ
[4] http://www.eeci-institute.eu/pdf/M5-textes/M5_slides4.pdf
matplotlibのインタラクティブなプロットを作る覚書(スクロールでズーム、ドラッグで移動)
背景
オレオレGUIを作る際にインタラクティブなPlotがしたいという動機です。
インタラクティブなPlotについては下記が結構ボリュームがあって良いと思います。
サンプルコード①:スクロールで拡大縮小、ドラッグで移動
下記StackOverflowの議論からコードをもらってPython3用に改変しました。
動作は下記の2つで、それぞれ関数が割り当てられています。
- スクロールで拡大縮小
- クリック&ドラッグで移動
from matplotlib.pyplot import figure, show import numpy class ZoomPan: def __init__(self): self.press = None self.cur_xlim = None self.cur_ylim = None self.x0 = None self.y0 = None self.x1 = None self.y1 = None self.xpress = None self.ypress = None def zoom_factory(self, ax, base_scale = 2.): def zoom(event): cur_xlim = ax.get_xlim() cur_ylim = ax.get_ylim() xdata = event.xdata # get event x location ydata = event.ydata # get event y location if event.button == 'down': # deal with zoom in scale_factor = 1 / base_scale elif event.button == 'up': # deal with zoom out scale_factor = base_scale else: # deal with something that should never happen scale_factor = 1 print(event.button) new_width = (cur_xlim[1] - cur_xlim[0]) * scale_factor new_height = (cur_ylim[1] - cur_ylim[0]) * scale_factor relx = (cur_xlim[1] - xdata)/(cur_xlim[1] - cur_xlim[0]) rely = (cur_ylim[1] - ydata)/(cur_ylim[1] - cur_ylim[0]) ax.set_xlim([xdata - new_width * (1-relx), xdata + new_width * (relx)]) ax.set_ylim([ydata - new_height * (1-rely), ydata + new_height * (rely)]) ax.figure.canvas.draw() fig = ax.get_figure() # get the figure of interest fig.canvas.mpl_connect('scroll_event', zoom) return zoom def pan_factory(self, ax): def onPress(event): if event.inaxes != ax: return self.cur_xlim = ax.get_xlim() self.cur_ylim = ax.get_ylim() self.press = self.x0, self.y0, event.xdata, event.ydata self.x0, self.y0, self.xpress, self.ypress = self.press def onRelease(event): self.press = None ax.figure.canvas.draw() def onMotion(event): if self.press is None: return if event.inaxes != ax: return dx = event.xdata - self.xpress dy = event.ydata - self.ypress self.cur_xlim -= dx self.cur_ylim -= dy ax.set_xlim(self.cur_xlim) ax.set_ylim(self.cur_ylim) ax.figure.canvas.draw() fig = ax.get_figure() # get the figure of interest # attach the call back fig.canvas.mpl_connect('button_press_event',onPress) fig.canvas.mpl_connect('button_release_event',onRelease) fig.canvas.mpl_connect('motion_notify_event',onMotion) #return the function return onMotion fig = figure() ax = fig.add_subplot(111, xlim=(0,1), ylim=(0,1), autoscale_on=False) ax.set_title('Click to zoom') x,y,s,c = numpy.random.rand(4,200) s *= 200 ax.scatter(x,y,s,c) scale = 1.1 zp = ZoomPan() figZoom = zp.zoom_factory(ax, base_scale = scale) figPan = zp.pan_factory(ax) show()
出力は下記のようになります。

ズーム動作
関数の最初にzoom用の関数を定義して、下記のコードでコールバック関数として渡しているのがわかります。
fig.canvas.mpl_connect('scroll_event', zoom)
そして、受け手の関数では変数eventから得られるスクロールの上下に関する情報をもとに図の拡大縮小を行っています。
ドラッグ動作
一方ドラッグ動作では、クリックされたときと離されたとき、マウスをドラッグしたときの動作にそれぞれ関数を割り当てて、 コールバックを呼んでいます。
# attach the call back
fig.canvas.mpl_connect('button_press_event',onPress)
fig.canvas.mpl_connect('button_release_event',onRelease)
fig.canvas.mpl_connect('motion_notify_event',onMotion)
その他の動作
つまり、どんなイベントがあるかだけ把握すれば適切なコールバック関数を渡してあげることでいろいろな動作ができるということです。
では、実際にどんなイベントがあるかについては下記公式ページを参照してください。
次のサンプルではkey_press_eventを使います。
GUI動作は組み合わせで行うことが多いのでサンプルコードのようにクラスを定義してその中でどのボタンがホールドされているかなどの変数を保持しておくと捗ると思います。
サンプルコード②:スクロールで左右ズーム、Ctrl押しながらのスクロールで上下ズーム
先程のコードを時系列Plot用に改良しました。
主な動作としては下記の通りになります。
- スクロール:X軸のみズーム
- Ctrl+スクロール:Y軸のみズーム
- ドラッグ:並行移動
- 「r」キー:描画範囲リセット
from matplotlib.pyplot import figure, show import numpy import matplotlib matplotlib.use('TKAgg') class ZoomPan: def __init__(self,ax): self.press = None self.cur_xlim = None self.cur_ylim = None self.x0 = None self.y0 = None self.x1 = None self.y1 = None self.xpress = None self.ypress = None self.ctrl_press = False self.ax = ax self.orig_xlim = ax.get_xlim() self.orig_ylim = ax.get_ylim() self.zoom_factory(ax,base_scale=1.1) self.ctrl_key(ax) self.pan_factory(ax) def zoom_factory(self, ax, base_scale = 2.): def zoomX(event,scale_factor): cur_xlim = ax.get_xlim() xdata = event.xdata # get event x location new_width = (cur_xlim[1] - cur_xlim[0]) * scale_factor relx = (cur_xlim[1] - xdata)/(cur_xlim[1] - cur_xlim[0]) ax.set_xlim([xdata - new_width * (1-relx), xdata + new_width * (relx)]) ax.figure.canvas.draw() def zoomY(event,scale_factor): cur_ylim = ax.get_ylim() ydata = event.ydata # get event y location new_height = (cur_ylim[1] - cur_ylim[0]) * scale_factor rely = (cur_ylim[1] - ydata)/(cur_ylim[1] - cur_ylim[0]) ax.set_ylim([ydata - new_height * (1-rely), ydata + new_height * (rely)]) ax.figure.canvas.draw() def zoom(event): if event.button == 'down': # deal with zoom in scale_factor = 1 / base_scale elif event.button == 'up': # deal with zoom out scale_factor = base_scale else: # deal with something that should never happen scale_factor = 1 print(event.button) ####### Switch zoom X or Y ######### if self.ctrl_press: zoomY(event,scale_factor) else: zoomX(event,scale_factor) fig = ax.get_figure() # get the figure of interest fig.canvas.mpl_connect('scroll_event', zoom) return zoom def ctrl_key(self,ax): def onPress(event): #print(event.key) if event.inaxes != ax: return if event.key == "control": self.ctrl_press = True elif event.key == "r": # reset zoom ax.set_xlim(self.orig_xlim) ax.set_ylim(self.orig_ylim) ax.figure.canvas.draw() def onRelease(event): #print(event.key) if event.inaxes != ax: return if event.key == "control": self.ctrl_press = False fig = ax.get_figure() # get the figure of interest # attach the call back fig.canvas.mpl_connect('key_press_event',onPress) fig.canvas.mpl_connect('key_release_event',onRelease) def pan_factory(self, ax): def onPress(event): if event.inaxes != ax: return self.cur_xlim = ax.get_xlim() self.cur_ylim = ax.get_ylim() self.press = self.x0, self.y0, event.xdata, event.ydata self.x0, self.y0, self.xpress, self.ypress = self.press def onRelease(event): self.press = None ax.figure.canvas.draw() def onMotion(event): if self.press is None: return if event.inaxes != ax: return dx = event.xdata - self.xpress dy = event.ydata - self.ypress self.cur_xlim -= dx self.cur_ylim -= dy ax.set_xlim(self.cur_xlim) ax.set_ylim(self.cur_ylim) ax.figure.canvas.draw() fig = ax.get_figure() # get the figure of interest # attach the call back fig.canvas.mpl_connect('button_press_event',onPress) fig.canvas.mpl_connect('button_release_event',onRelease) fig.canvas.mpl_connect('motion_notify_event',onMotion) #return the function return onMotion fig = figure() ax = fig.add_subplot(111, xlim=(0,1), ylim=(0,1), autoscale_on=False) ax.set_title('Click to zoom') x,y,s,c = numpy.random.rand(4,200) s *= 200 ax.scatter(x,y,s,c) scale = 1.1 zp = ZoomPan(ax) show()
key_press_event を使ったフラグ管理と注意点
コントロールキーを押しているか管理するためにkey_press_eventを使っています。
キーが押されたらフラグを立てて、キーを話したらフラグを下ろすという2つのコールバックを定義しています。 その他に「r」を押した際に描画範囲をリセットする機能も同時に書いています。
ハマったバグ
Macで開発しているときにハマったのがOS Xのバックエンドだとcontrolキーが押されたかチェックできない問題です。
python - Close pyplot figure using the keyboard on Mac OS X - Stack Overflow
上記の質疑のようにバックエンドをTKAggに変えてことなきを得ました。ちょっと画質が荒くなる感じがしてあまり好きではありませんが。。。
import matplotlib
matplotlib.use('TKAgg')
これ以外にもキーの同時押しのときはバックエンドによって出てくる値が変わるなどこのあたりは結構気をつけることがありそうです。
スマホ外付けの望遠レンズで月は撮れるか(OpenCVで実倍率を検証)
概要
スマホの外付けレンズというのが果たして実用に堪えるのか前から気になっていたので夏休みに買ってみて検証してみました。
先に所感をまとめると以下のとおりです。
- クリップは固定に不安
- 望遠とマクロはそこそこ楽しい
- 真面目にやるなら三脚は必須
- 中華のズーム倍率は信用してはいけない
また,一応スマホでも月は撮れます。

スマホと外付けレンズ
検証に用いたのは下記のレンズキットです。

自称望遠22倍,マクロ,広角,魚眼レンズを備えているということでした。
また,スマホとしてPixel4とHuaweiのNova3を用いました。
レンズを使ってみての感想
100円レンズだと曇ったり周辺がぼやけたりするそうですが,全般的にレンズをつけて著しく画質が劣化するということはなかったです。
ただ,広角も魚眼レンズもほしい場面があまりなく後述のクリップの手間を考えても持ち運んで気軽にスマホにつけるというような運用ではないと思いました。
| レンズ | おすすめ度 | 感想 |
|---|---|---|
| 広角 | △ | 広角で撮りたいシーンが自撮りくらいしか思いつかない。 |
| 魚眼 | ✕ | ちゃんと魚眼になるけど何に使うのか不明。 |
| マクロ | ◎ | スマホでマクロ撮影できるのは意外と楽しい。位置合わせも楽。 |
| 望遠 | ○ | ちゃんとセッティングすれば結構遊びがいがある。が,準備がだるい。 |

クリップの使用感
商品写真の通り,クリップにレンズをはめてスマホのカメラと位置合わせをすることで撮影ができます。 これは正直慣れが必要で,
- 位置合わせが難しい(特に望遠レンズ)
- 望遠レンズ着用時は自重でズレが起きやすい
という問題があるため,特に望遠レンズで「正しくはめて」「正しく目標物に向ける」というプロセスが非常に撮影において時間がかかります。
もう少しきちんとした三脚があるとこのあたりの安定度が全然違うので,望遠レンズを使う方は今後のカメラ購入も見越して用意しておいたほうがいいと思います。

冒頭の画像はセッティングに5分程度かかっており,初めての場合はもっと掛かると思ったほうが良さそうです。
望遠倍率が表記と違う問題
商品説明では22倍ズームとあるのですが正直そんなにズームしている感じはしませんでした。 口コミでも倍率が低めとあったのでOpenCVを使って確認してみます。
特徴点のマッチングを用いてレンズの有無の画像の間の倍率を計算すると大体9.72倍と出ました。 22倍とは…

この手の商品あるあるとして,1つのコア技術の製造元に対して外装をちょっと変更していろんな業者が売るという構造になっている事が多いので他の似た製品でも望遠レンズの倍率はせいぜい10倍弱になっているというのはあると思います。
製品仕様くらいはきちんと記述してほしいです。
参考:一眼レフで撮るとこうなる
いろいろあってSONYのα6400というカメラを手に入れました。

で、これで月を撮るとこんな感じになりました。

一番感動したのは手ブレ補正か倍率低さのおかげか三脚なしの手持ちでちゃんと撮影できたことです。 スマホの設定だと基本的に露光が長くなるので三脚なしはありえないのでこのあたりの撮影の手間は断然こちらの方が楽でした。
ちなみにコンデジで撮ると下記のような感じになります。
まとめ
ということで今回の所感です。
- 安い外付けレンズでもスマホで月を撮れるが設備投資(特に三脚)が必要。
- マクロと望遠意外は特に用がなさそう。
- 望遠倍率だいたいサバ読んでる。
- 一眼レフはいいぞ。